
개요
Windows 11에 Ollama를 설치하고 Qwen3:8B 모델을 로컬에서 실행하는 전체 과정을 정리한다.
정리
1. Ollama 소개
Ollama는 로컬 환경에서 LLM을 실행할 수 있게 해주는 도구다. 클라우드 API 없이도 터미널에서 바로 대화형 AI를 사용할 수 있고, NVIDIA GPU가 있으면 자동으로 GPU 가속을 활용한다.
로컬 LLM 실행의 장점은 아래와 같다.
- 인터넷 연결 없이 사용 가능하다
- 데이터가 외부로 전송되지 않는다
- API 비용이 발생하지 않는다
- REST API를 제공하므로 다른 앱과 연동할 수 있다
2. 시스템 요구사항
Ollama는 CPU만으로도 동작하지만 GPU가 있으면 훨씬 빠르다.
| 항목 | 최소 사양 | 권장 사양 |
|---|---|---|
| OS | Windows 10 이상 | Windows 11 |
| RAM | 8GB | 16GB 이상 |
| GPU | 없어도 가능 | NVIDIA(VRAM 8GB 이상) |
| 디스크 | 10GB 여유 공간 | SSD 권장 |
이 포스트에서 사용한 환경은 아래와 같다.
- CPU: AMD Ryzen 5 7500F
- GPU: NVIDIA RTX 4070(VRAM 12GB)
- RAM: 32GB
- OS: Windows 11 64bit
3. Ollama 설치
ollama.com/download에서 Windows용 설치 파일을 다운로드한다. OllamaSetup.exe를 실행하면 별도 설정 없이 설치가 완료된다.
설치가 끝나면 PowerShell에서 버전을 확인한다.
ollama --version
ollama version is 0.16.3처럼 버전이 출력되면 설치가 정상적으로 완료된 것이다.
4. Qwen3:8B 모델 실행
Qwen3:8B는 Alibaba Cloud에서 공개한 80억 파라미터 모델이다. 한국어를 포함한 다국어를 지원하며 8B 크기임에도 성능이 준수하다.
아래 명령어 하나로 모델 다운로드와 대화형 채팅이 동시에 시작된다.
ollama run qwen3:8b
처음 실행하면 모델을 다운로드한다(약 5GB). 다운로드가 끝나면 바로 대화를 시작할 수 있다.
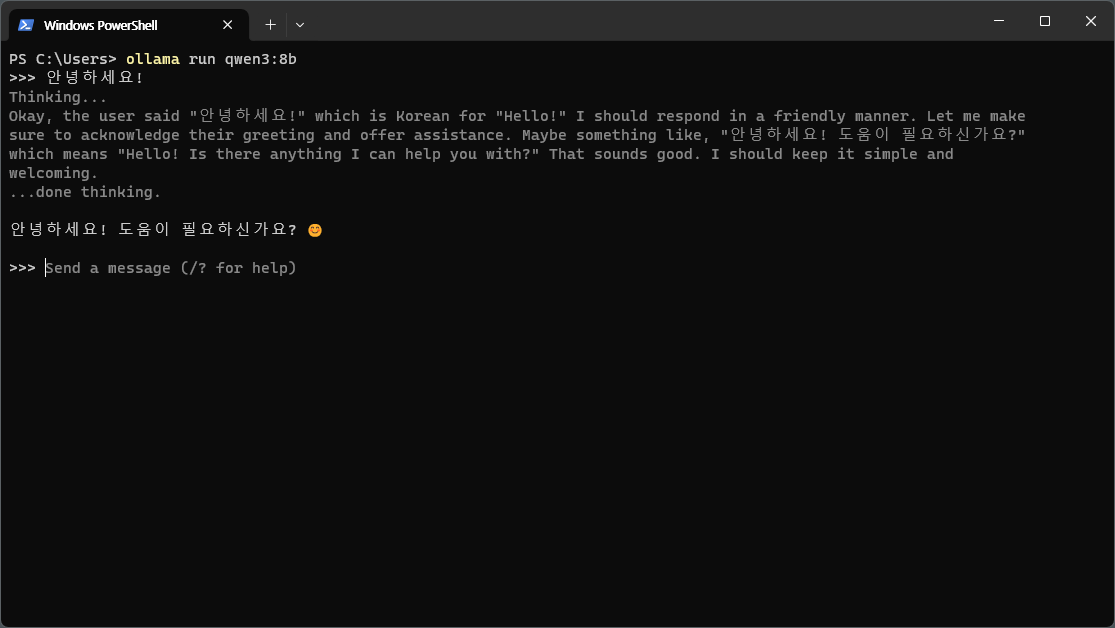
Qwen3는 기본적으로 thinking 모드가 활성화되어 있어서 Thinking... 과정을 거친 후 응답한다. 대화를 종료하려면 /bye를 입력한다.
5. GPU 활용 확인
Ollama는 NVIDIA GPU를 자동으로 감지하여 사용한다. nvidia-smi 명령어로 VRAM 사용량을 확인할 수 있다.
nvidia-smi
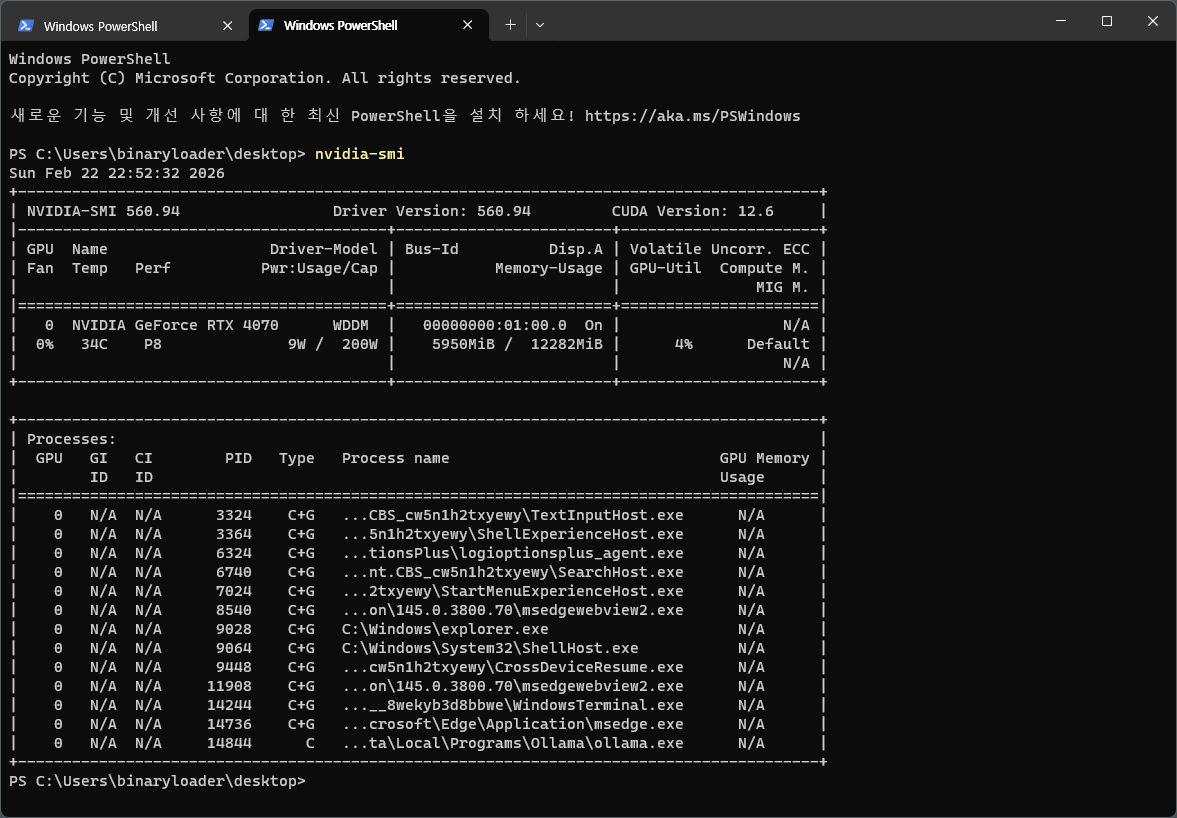
Qwen3:8B 모델은 약 6GB의 VRAM을 사용한다. RTX 4070 12GB 기준으로 여유가 충분하다.
6. 기본 사용법
6.1. 대화형 채팅
ollama run 명령어로 대화형 모드에 진입한다.
ollama run qwen3:8b
대화 중 사용할 수 있는 명령어는 아래와 같다.
/bye— 대화 종료/clear— 대화 기록 초기화/set parameter temperature 0.7— 파라미터 변경
6.2. REST API
Ollama는 설치와 동시에 localhost:11434에 API 서버를 자동으로 실행한다. 다른 앱이나 스크립트에서 바로 호출할 수 있다.
$body = '{"model":"qwen3:8b","prompt":"Explain how to set environment variables on Windows. Answer in Korean.","stream":false}'
Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -ContentType "application/json" -Body $body
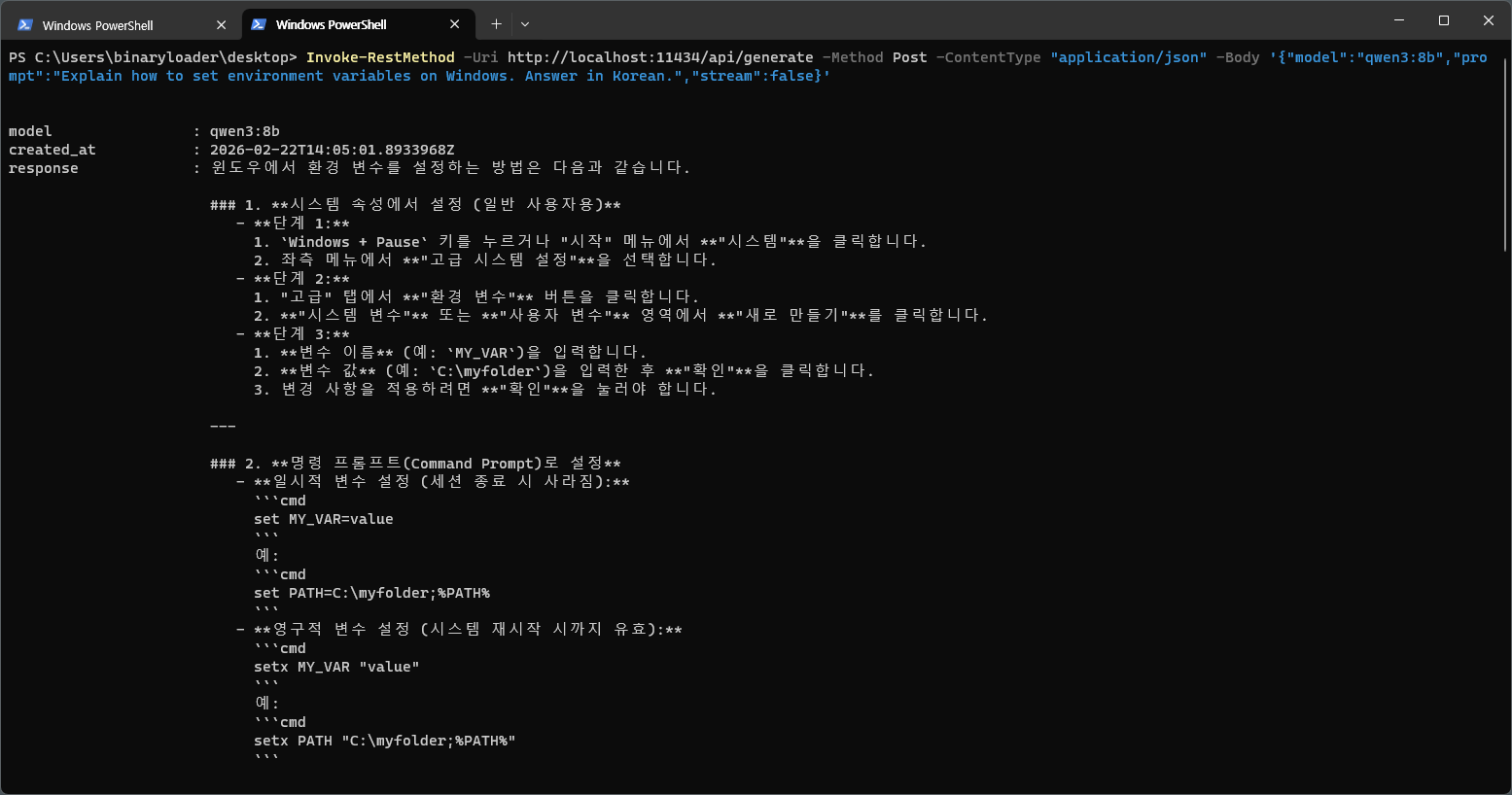
7. 유용한 명령어
| 명령어 | 설명 |
|---|---|
ollama list |
설치된 모델 목록 확인 |
ollama pull qwen3:8b |
모델 다운로드(실행 없이) |
ollama rm qwen3:8b |
모델 삭제 |
ollama show qwen3:8b |
모델 상세 정보 확인 |
ollama ps |
실행 중인 모델 확인 |
ollama stop qwen3:8b |
모델 중지 |




댓글남기기