
개요
잠이 안 오는 야심한 새벽에 Claude Code CLI의 입출력을 음성으로 중계하는 macOS 어시스턴트 데모를 만들어 봤다. whisper.cpp로 음성을 텍스트로 바꾸고 Google Cloud TTS로 응답을 읽어주는 수준이지만 만드는 과정이 재밌었다.
발단
새벽 2시쯤이었다. 자려고 누웠는데 잠이 안 온다. 뒤척이다가 결국 포기하고 노트북을 켰다. 개발자에게 잠 못 드는 밤은 곧 사이드 프로젝트의 시작이다.
요즘 Claude Code를 거의 하루 종일 쓰고 있다. 코드 검색, 리팩터링, 디버깅까지 터미널에서 텍스트로 주고받는 방식인데 문득 이런 생각이 들었다. 여기에 마이크로 말을 걸고 스피커로 답을 들을 수 있으면 어떨까?
실용적이냐고 물으면 솔직히 아니다. 코드는 눈으로 봐야 하고 터미널 출력을 음성으로 듣는 건 비효율적이다. 하지만 “현재 브랜치 뭐야?” “이 파일 열어줘” 같은 간단한 명령이나 “방금 변경 사항 요약해 줘” 같은 확인 작업은 음성이 더 편할 수도 있겠다 싶었다. 솔직히 실용성보다는 그냥 만들어 보고 싶었다. 새벽에 이런 거 만들면서 혼자 킥킥거리는 게 이 직업의 묘미 아닐까.
이불 속에서 대충 머릿속으로 구조를 그렸다. STT는 Whisper, TTS는 Google Cloud, Claude Code는 CLI subprocess로 붙이면 되겠다. 생각보다 조각이 깔끔하게 맞아떨어지는 느낌이 들어서 바로 작업에 들어갔다.
설계
1. 전체 구조
Xcode 프로젝트 없이 Swift Package Manager만으로 구성한 macOS 네이티브 앱이다. SwiftUI 기반이고 macOS 15 이상을 타겟으로 한다. 외부 Swift 패키지 의존성은 없다. STT는 whisper.cpp 바이너리를 subprocess로 실행하고 TTS는 Google Cloud REST API를 호출하기 때문에 SPM 의존성이 필요 없었다. 새벽에 의존성 관리까지 하고 싶지 않았던 것도 이유긴 하다.
앱은 두 가지 인터페이스로 구성된다. 메뉴바를 클릭하면 사용량 대시보드가 팝오버로 표시되고 글로벌 단축키(⌥⌘V)를 누르면 플로팅 어시스턴트 패널이 열린다. 대시보드는 이전에 만들었던 Claude 사용량 모니터를 그대로 가져왔고 어시스턴트 패널이 이번에 새로 추가한 부분이다.
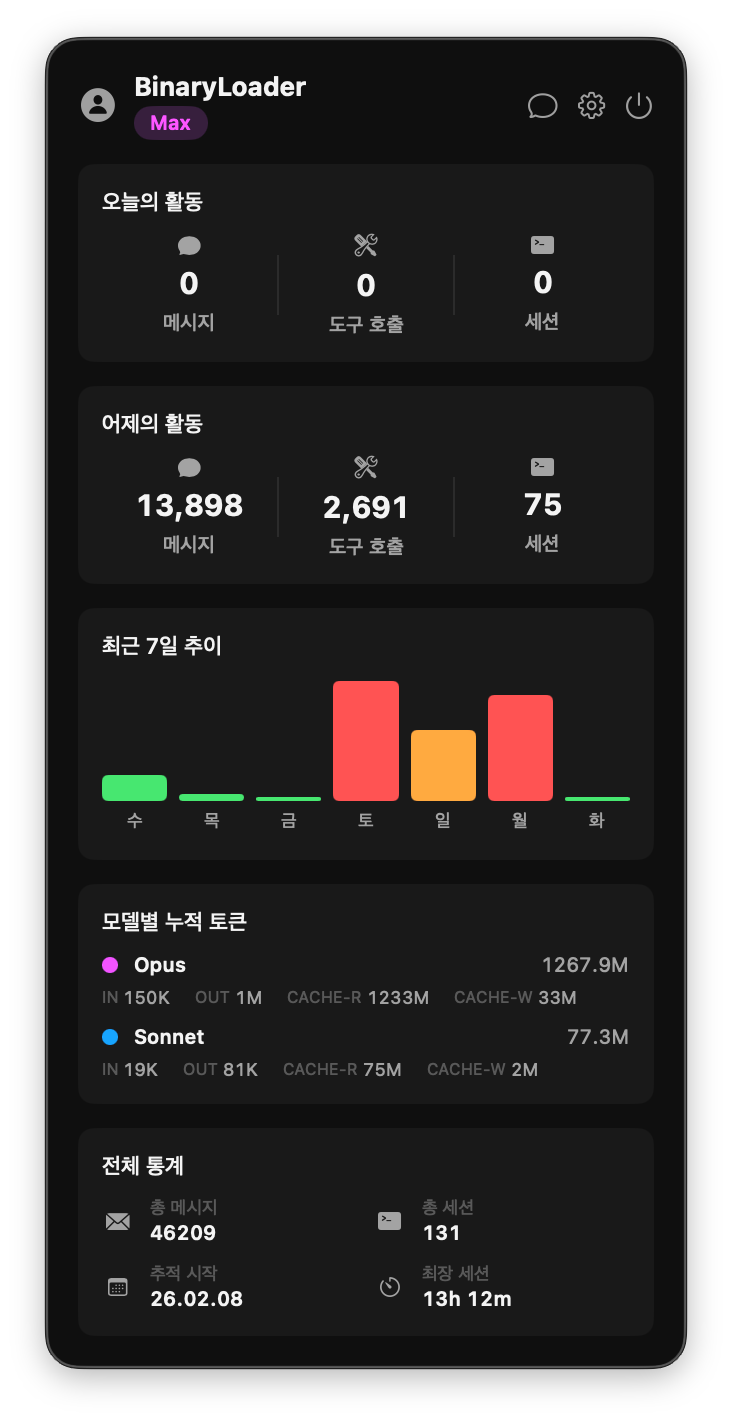 메뉴바 클릭 시 표시되는 사용량 대시보드
메뉴바 클릭 시 표시되는 사용량 대시보드
서비스 계층은 Protocol로 추상화했다. 음성 인식(SpeechRecognizing), 음성 합성(SpeechSynthesizing), Claude Code 실행(ClaudeCodeExecuting), 단축키 감지(HotkeyListening), 권한 관리(PermissionChecking)에 대해 각각 프로토콜을 정의하고 구체적인 구현을 주입하는 방식이다. 예를 들어 SpeechRecognizing 프로토콜은 startListening()과 stopListening()만 정의하고 구체적인 Whisper 연동은 WhisperService가 담당한다. 나중에 다른 STT 엔진으로 교체할 때 수정 범위를 줄이려는 의도다.
ServiceContainer가 모든 의존성을 조립한다. TTS API 키나 음성 설정은 UserDefaults에서 읽어오고 ServiceContainer 초기화 시점에 각 서비스에 주입된다. AppDelegate가 이 컨테이너를 통해 ViewModel을 구성하고 ViewModel이 View에 연결되는 구조다. 새벽에 만드는 데모 프로젝트치고는 구조가 과한 감이 있지만 나중에 뭘 바꾸더라도 한 곳만 건드리면 된다는 게 편했다.
2. 상태 머신
어시스턴트의 동작은 다섯 가지 상태를 전이하는 유한 상태 머신으로 관리한다.
대기(idle) 상태에서 단축키를 누르면 듣기(listening) 상태로 전환된다. 사용자가 말을 마치면 처리(processing) 상태로 넘어가 Claude Code가 응답을 생성한다. 응답이 준비되면 말하기(speaking) 상태에서 TTS로 음성을 재생하고 다시 대기 상태로 돌아온다. 어느 상태에서든 에러가 발생하면 에러(error) 상태로 전환되며 재시도하거나 취소해 대기 상태로 복귀할 수 있다.
처음에는 상태 머신 없이 그냥 Bool 플래그 몇 개로 관리하려 했다. isListening, isProcessing, isSpeaking 같은 식으로. 그런데 작업하다 보니 “녹음 중에 또 녹음 요청이 오면?” “TTS 재생 중에 새로운 응답이 오면?” 같은 엣지 케이스가 계속 생겨서 결국 상태 머신으로 갈아탔다. 상태 전이 로직은 현재 상태와 이벤트의 조합으로 다음 상태를 결정하고 허용되지 않은 전이는 nil을 반환해서 그냥 무시한다. 덕분에 비동기 흐름이 복잡해져도 상태를 추적하기 수월하다.
한 가지 삽질했던 부분은 processing에서 speaking으로의 전환이다. Claude Code 응답 수신과 TTS 합성이 같은 Task 안에서 연속으로 일어나는데 상태가 바뀔 때마다 activeTask를 cancel하는 로직을 넣어뒀더니 TTS 합성까지 같이 취소되는 문제가 생겼다. 새벽 3시에 “왜 소리가 안 나지?”를 한참 디버깅하다가 이 전환에서만 예외적으로 기존 Task를 유지하도록 처리해서 해결했다.
 대기 상태 — 단축키를 누르면 음성 입력이 시작된다
대기 상태 — 단축키를 누르면 음성 입력이 시작된다
3. 음성 입력 — whisper.cpp
STT는 whisper.cpp를 사용한다. 처음에는 Apple의 Speech 프레임워크를 써봤는데 영어에서는 괜찮지만 한국어 짧은 문장에서 인식률이 영 아쉬웠다. “현재 브랜치 알려줘”를 “현재 분란 치 알려줘”로 알아듣는 걸 보고 바로 Whisper로 갈아탔다. large-v3-turbo 모델은 로컬에서 돌아감에도 한국어 인식 정확도가 나쁘지 않았다. 네트워크 없이도 작동하는 건 덤이다.
동작 방식은 Push-to-Talk이다. ⌥⌘V를 누르고 있으면 녹음이 시작되고 손을 떼면 녹음이 끝난다. 단축키 감지에는 CGEvent tap을 사용했다. 처음에는 NSEvent의 글로벌 모니터로 했는데 modifier 키 조합의 keyDown/keyUp을 제대로 잡지 못해서 Push-to-Talk이 안 됐다. CGEvent tap은 더 저수준이지만 이벤트를 소비(nil 반환)할 수 있어서 단축키를 누르는 동안 다른 앱에 키 입력이 전달되지 않도록 막을 수 있다.
녹음된 오디오는 AVAudioEngine의 inputNode에 tap을 설치해 캡처한다. Whisper가 mono 입력을 요구하므로 1채널 포맷으로 받는다. 설정에서 마이크를 선택할 수 있게 CoreAudio의 AudioUnit 프로퍼티를 직접 건드려서 입력 디바이스를 변경하게 했다.
캡처된 CAF 파일은 macOS 내장 유틸리티인 afconvert로 16kHz 16-bit mono WAV로 변환된다. Whisper가 이 포맷을 요구하기 때문이다. 변환 후에는 ffmpeg로 3초 이상 이어지는 무음 구간을 제거하는 전처리를 거친다.
Whisper 모델에는 hallucination이라는 골치 아픈 문제가 있다. 아무 말도 하지 않았는데 무음 입력에서 환청처럼 “감사합니다” “구독과 좋아요 부탁드립니다” 같은 문장을 만들어내는 것이다. YouTube 자막 학습 데이터의 영향으로 보이는데 처음 봤을 때는 좀 소름이 돋았다. 이걸 잡겠다고 안전장치를 겹겹이 쌓아야 했다. 녹음 시간이 0.8초 미만이거나 피크 오디오 레벨이 임계값 이하면 전사 자체를 건너뛴다. 무음 제거 후 파일 크기가 10KB 미만이면 역시 건너뛴다. whisper.cpp 실행 시 -nt(타임스탬프 없음)와 -mc 0(컨텍스트 누적 없음) 플래그로 모델이 이전 출력에 끌려가지 않도록 했다. 이것저것 다 적용하고 나서야 겨우 안정적으로 동작했다.
 음성 입력 중 — 아바타가 귀를 기울이고 있다
음성 입력 중 — 아바타가 귀를 기울이고 있다
4. 음성 출력 — Google Cloud TTS
TTS는 Google Cloud Text-to-Speech의 Chirp 3 HD 모델을 사용한다. Apple의 내장 TTS도 시도해 봤지만 한국어 음성이 너무 기계적이었다. Chirp 3 HD는 Google이 2025년에 출시한 모델인데 억양과 호흡이 꽤 자연스럽다. 처음 들었을 때 “오 이 정도면 괜찮은데?” 싶었다. 가격 페이지를 확인해 보니 매월 0~100만 자까지 무료 사용량이 제공돼서 데모 프로젝트에 부담 없이 쓸 수 있었다.
설정 화면에서 음성을 선택하고 미리 들어볼 수 있게 했다. Chirp 3 HD는 남녀 음성을 포함해 다양한 프리셋을 제공하는데 각각 고유한 이름(Alnilam, Charon 등)이 붙어 있다. API 호출 시 LINEAR16(비압축 PCM) 인코딩에 48kHz 샘플레이트를 지정해서 가능한 한 좋은 음질로 받는다.
Claude Code의 응답에서 TTS용 텍스트를 분리하는 부분이 은근 재밌었다. Claude의 응답에는 코드 블록, 파일 경로, 마크다운 문법 같은 것들이 잔뜩 섞여 있어서 그대로 읽히면 곤란하다. 시스템 프롬프트에 응답 끝에 [TTS]...[/TTS] 마커를 삽입하도록 지시하고 마커 안에는 핵심 내용만 자연스러운 구어체로 넣도록 했다. 쉼표를 최소화하고 숫자는 한국어 발음으로 쓰고 특수 부호를 사용하지 않는 규칙도 정해 두었는데 이 규칙들을 하나하나 다듬는 과정이 꽤 손이 갔다.
시행착오도 있었다. 처음에는 TTS 오디오를 바로 재생했더니 첫 0.5초 정도가 잘려서 들렸다. “좋은 아침입니다”가 “침입니다”로 들리는 거다. macOS의 오디오 하드웨어가 깨어나는 데 시간이 걸리는 것이 원인이었다. 해결 방법은 WAV 데이터 앞에 300밀리초의 무음을 삽입하는 것이었는데 이게 생각보다 간단하지 않았다. WAV 파일에는 RIFF 헤더가 있고 헤더 안에 전체 파일 크기와 데이터 청크 크기가 기록되어 있다. 무음을 삽입하면 이 값들을 바이트 단위로 직접 수정해야 한다. Raw PCM 응답인 경우에는 단순히 앞에 0 바이트를 붙이면 되지만 WAV 헤더가 있는 경우에는 offset 4(RIFF 크기)와 offset 40(데이터 청크 크기)을 갱신해야 한다. 사실 이 바이트 오프셋 계산은 내가 한 게 아니라 Claude Code가 해줬다. 새벽 4시에 옆에서 “소리가 안 나” “앞이 잘려” 하고 투덜거렸더니 알아서 헤더를 뜯어 고쳤다. 소리가 제대로 나오는 순간의 쾌감은 꽤 컸다.
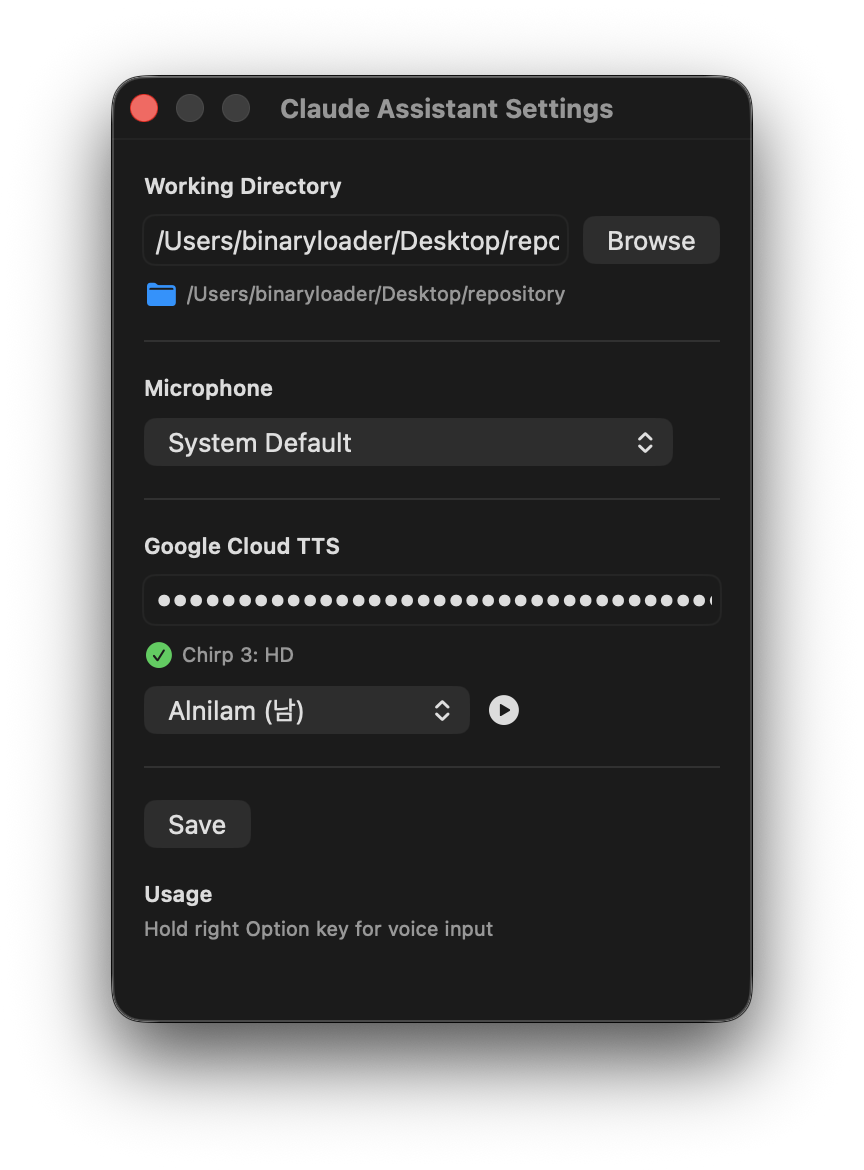 Google Cloud TTS 설정 — 음성 선택과 미리 듣기를 지원한다
Google Cloud TTS 설정 — 음성 선택과 미리 듣기를 지원한다
5. 아바타
어시스턴트에 아바타를 넣은 건 완전히 재미 목적이다. 기능적으로는 전혀 필요 없지만 새벽 작업의 묘미는 이런 쓸데없는 데 시간을 쓸 수 있다는 것 아닌가. SwiftUI로 그린 둥근 얼굴에 안경을 쓴 캐릭터인데 상태에 따라 표정이 바뀐다.
표정은 FaceExpression이라는 구조체로 정의된다. 눈의 세로 크기(eyeScaleY), 눈동자 위치(pupilOffsetX/Y), 눈썹 높이와 각도(eyebrowOffsetY, eyebrowLeftAngle, eyebrowRightAngle), 입의 벌림 정도(mouthOpen), 미소 정도(mouthSmile) 같은 파라미터의 조합이다. 대기 상태에서는 이 파라미터를 랜덤으로 조합한 14가지 표정을 1.8초 간격으로 번갈아 보여준다. 약간 눈을 감거나 한쪽 눈썹을 올리거나 시선을 돌리는 식의 미세한 변화다.
듣기 상태에서는 눈이 커지고(eyeScaleY: 1.15) 귀에 손을 대는 제스처가 나타난다. 손 모양은 타원형 손바닥 위에 세 개의 캡슐 모양 손가락을 올려 간단하게 표현했다. 처리 상태에서는 눈동자가 sin/cos 함수를 따라 원을 그리며 생각하는 표현을 하고 도구 활동에 “검색”이 포함되면 눈동자가 좌우로 빠르게 왕복하는 별도의 애니메이션이 적용된다. 코드 수정이나 파일 작성 중에는 눈썹이 모이고 눈이 약간 좁아지는 집중 표정이 된다.
말하기 상태에서는 입이 0.16초 간격으로 랜덤한 크기(0~0.6)로 열렸다 닫혔다 한다. 입 모양은 MouthShape라는 커스텀 Shape으로 구현했는데 openAmount와 smile 두 파라미터를 AnimatableData로 선언해서 SwiftUI의 spring 애니메이션이 자연스럽게 적용된다.
여기서 멈추면 됐는데 새벽 텐션이란 게 있다. 2.5~5.5초 간격으로 랜덤하게 눈을 깜빡이고(눈꺼풀이 0.07초에 닫혔다가 0.12초에 열림) 호흡에 맞춰 몸 전체가 0.985~1.015 범위에서 미세하게 확대 축소되는 애니메이션까지 넣었다. 아무도 신경 쓰지 않을 디테일이지만 이런 걸 만지작거리는 시간이 이 프로젝트에서 제일 즐거웠다.
 응답 중 — 아바타가 입을 움직이며 TTS 텍스트가 함께 표시된다
응답 중 — 아바타가 입을 움직이며 TTS 텍스트가 함께 표시된다
6. Claude Code 연동
핵심은 Claude Code CLI를 subprocess로 실행하는 것이다. --print 플래그로 비대화형 모드로 실행하고 --output-format stream-json으로 JSON 스트리밍 응답을 받는다. --continue 플래그로 이전 대화를 이어갈 수 있어서 맥락이 유지되는 연속 대화가 가능하다.
JSON 스트리밍 응답을 파싱하는 게 은근히 재밌는 작업이었다. Claude Code는 한 줄에 하나의 JSON 객체를 출력하는데 type 필드가 assistant이고 message.content 배열 안에 text 블록과 tool_use 블록이 섞여서 온다. tool_use 블록에서 도구 이름을 추출하면 현재 무엇을 하고 있는지 알 수 있다. Bash면 “명령어 실행 중…” Read면 “파일 읽는 중…” Grep이면 “코드 검색 중…” 같은 식으로 매핑해 두었다.
시스템 프롬프트에는 시간대별로 인사가 달라지는 페르소나를 설정했다. 새벽이면 “늦은 시간까지 수고하십니다” 아침이면 “좋은 아침입니다”라고 시작하고 보고식으로 간결하게 응답하며 과도한 사과나 설명은 하지 않도록 했다. 첫 대화에서만 인사하고 이후 연속 대화에서는 인사를 반복하지 않는 것도 자연스러움을 위한 디테일이다. 새벽에 “늦은 시간까지 수고하십니다”라는 인사를 처음 들었을 때 혼자 웃음이 나왔다.
여기서 한참을 잡아먹은 버그가 하나 있다. Claude Code CLI를 subprocess로 실행할 때 부모 프로세스의 환경 변수를 그대로 상속하면 문제가 생긴다. CLAUDE_CODE_ENTRYPOINT와 CLAUDECODE 환경 변수가 설정되어 있으면 Claude Code가 자신이 다른 Claude Code 인스턴스 안에서 실행되고 있다고 판단해 동작이 달라진다. 한참 동안 “왜 같은 명령인데 터미널에서는 되고 앱에서는 안 되지?”를 반복하다가 환경 변수를 덤프해 보고 나서야 원인을 찾았다. 이 변수들을 프로세스 환경에서 명시적으로 제거해야 독립적인 세션으로 실행된다.
7. 채팅 UI
어시스턴트 패널은 NSPanel을 사용한 플로팅 윈도우다. NSPanel의 .nonactivatingPanel 스타일을 사용하면 패널이 표시되어도 현재 작업 중인 앱의 포커스를 빼앗지 않는다. 코드를 작성하면서 옆에 어시스턴트를 띄워 놓고 쓰는 시나리오에 적합하다. .canJoinAllSpaces와 .fullScreenAuxiliary로 모든 데스크톱 스페이스와 전체 화면에서도 접근할 수 있게 했고 hidesOnDeactivate를 false로 설정해서 다른 앱으로 전환해도 패널이 사라지지 않도록 했다.
채팅 메시지는 카카오톡 스타일의 말풍선으로 표시된다. 사용자 메시지는 오른쪽 파란 말풍선에 흰색 글씨로 어시스턴트 메시지는 왼쪽 반투명 말풍선으로 나타난다. UnevenRoundedRectangle을 사용해서 말풍선의 꼬리 방향 모서리만 둥글기를 줄여 자연스러운 모양을 만들었다.
텍스트 입력도 지원한다. 음성만으로 모든 걸 할 수 있지만 조용한 환경이거나 긴 텍스트를 전달해야 할 때는 하단의 텍스트 필드를 통해 직접 입력할 수 있다. 이미지 첨부도 가능한데 NSOpenPanel로 이미지를 선택하면 메시지에 경로가 포함되어 Claude Code에 전달된다.
처리 중일 때는 Claude Code가 현재 어떤 도구를 사용하고 있는지 실시간으로 표시되는 인디케이터가 나타난다. 도구 종류에 따라 아이콘이 달라지는데 검색이면 돋보기 파일 읽기면 문서 코드 수정이면 연필 웹 검색이면 지구본 아이콘이 표시된다.
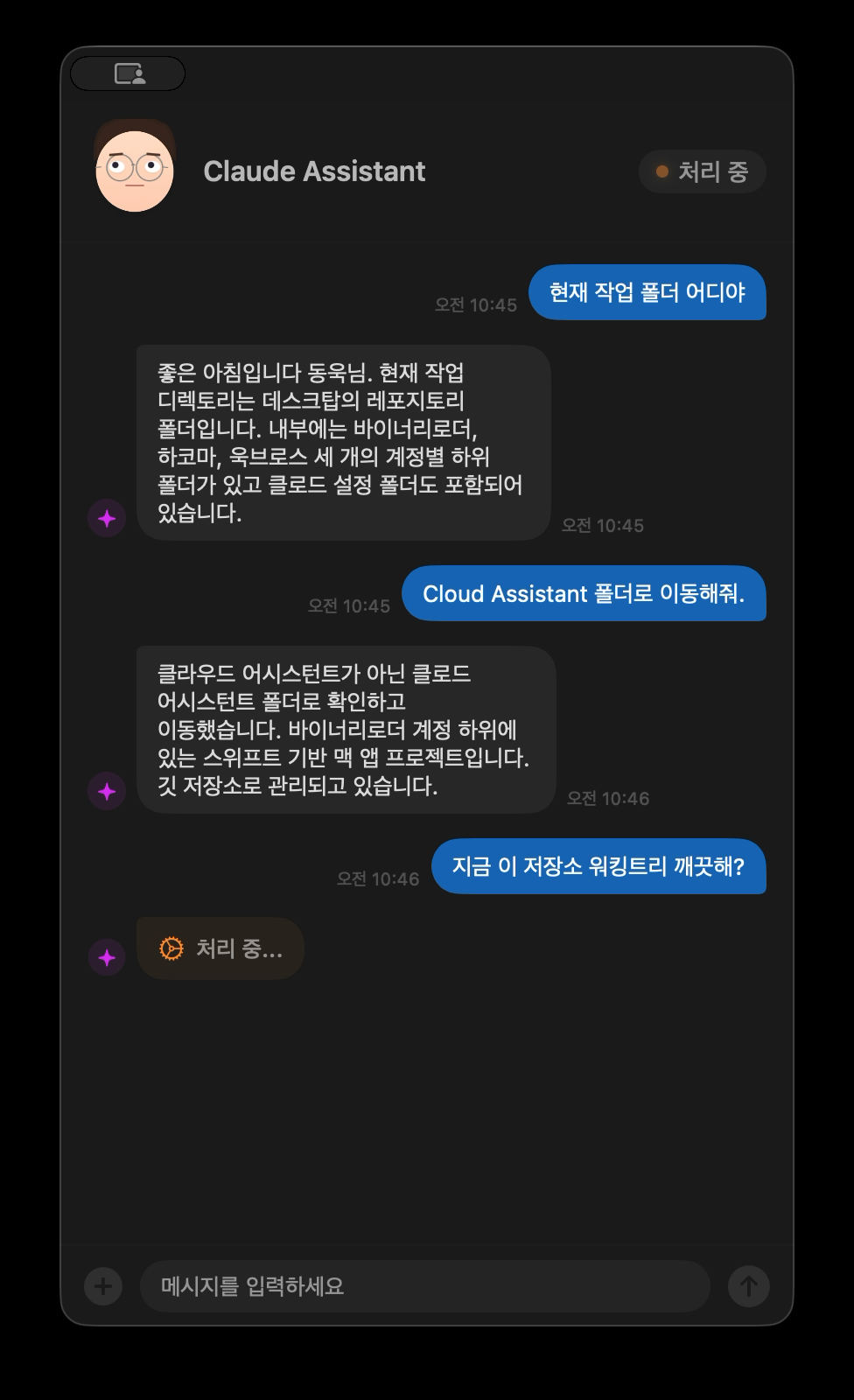 실제 대화 — 폴더 이동이나 상태 확인 같은 명령을 음성으로 처리한다
실제 대화 — 폴더 이동이나 상태 확인 같은 명령을 음성으로 처리한다
돌아보며
밤에 잠이 안 와서 시작한 데모 프로젝트치고는 생각보다 쓸 만하게 나왔다 재밌게 놀았다. “Claude Code에 음성을 입힐 수 있을까?”라는 질문에 대한 답 정도는 됐다.
실제로 사용해 보면 음성으로 “현재 작업 폴더 어디야”라고 물어보고 스피커에서 “현재 작업 디렉토리는 데스크탑의 레포지토리 폴더입니다”라는 답을 듣는 경험이 나름 신선하다. “이 저장소 워킹트리 깨끗해?”라고 물어보면 파일 상태를 확인한 뒤 구어체로 결과를 알려준다. 터미널에서 같은 작업을 할 수 있지만 손을 키보드에서 떼지 않아도 된다는 점에서 나름의 편의성이 있다.
다만 아쉬운 점은 응답 속도다. 음성으로 질문하면 Claude Code가 분석하고 도구를 호출하고 응답을 생성하기까지 시간이 꽤 걸린다. 단순한 질문에도 수 초에서 십수 초를 기다려야 하는데 음성 인터페이스에서 이 대기 시간은 체감이 크다.
지금은 whisper.cpp, Google Cloud TTS, Claude Code CLI를 순차적으로 파이프라인처럼 연결한 구조라서 각 단계의 지연이 그대로 누적된다. 완제품을 그냥 붙인 거라 이게 최선인가 싶기도 한데 개선 여지는 있을 것 같다. 엔지니어링 측면에서는 전체 응답을 기다리지 않고 첫 문장이 완성되는 시점부터 TTS를 시작하는 스트리밍 방식이나 processing 상태 진입 시점에 오디오 세션을 미리 초기화해서 재생 시작 지연을 없애는 방법 등이 있을 것 같다. LLM 활용 측면에서는 “현재 브랜치 알려줘” 같은 간단한 질의를 Haiku급 경량 모델로 분기하거나 음성 전용 시스템 프롬프트를 따로 두어 도구 호출 없이 짧게 답할 수 있는 질문과 분석이 필요한 질문을 구분하는 것도 생각해 볼 수 있다. git status나 현재 디렉토리 같은 자주 묻는 정보를 로컬에 미리 캐싱해 두고 LLM 호출 자체를 건너뛰는 방법도 있다. 지금은 데모 수준이라 여기까지 손대지는 않았지만 스트리밍 TTS만 구현해도 체감이 확 달라질 것 같다.
삽질이 제일 많았던 건 역시 Whisper hallucination이다. 안전장치 하나 추가하고 테스트하고 또 다른 패턴으로 뚫리고 다시 막고를 반복했다. TTS에서 첫 음절이 잘리는 것도 원인을 찾기까지 꽤 걸렸다. 오디오 하드웨어 초기화 지연이라는 건 로그만 봐서는 알 수 없었고 WAV에 무음을 삽입하는 해결책도 바이트 단위로 헤더를 수정해야 해서 간단하지 않았다.
반면 아바타 표정은 제일 쓸데없는 작업이면서 제일 재밌었다. 파라미터 몇 개 바꾸면서 “이거 귀엽다” “이건 좀 무섭다” 하며 혼자 놀았다. 새벽에 이런 걸 하고 있으면 시간이 순삭된다.
잠 못 드는 새벽 2시에 시작한 프로젝트가 해를 넘기고도 한참을 더 갔다. 자야 되는데, 아 벌써 오전 10시네? 그래도 꽤 재밌게 놀았다.




댓글남기기