
概要
Windows 11にOllamaをインストールし、Qwen3:8Bモデルをローカルで実行するまでの全手順をまとめる。
手順
1. Ollamaとは
Ollamaはローカル環境でLLMを実行できるツールだ。クラウドAPIなしでターミナルから直接対話型AIを使うことができ、NVIDIA GPUがあれば自動的にGPUアクセラレーションを活用する。
ローカルLLM実行のメリットは以下の通りだ。
- インターネット接続なしで使用可能
- データが外部に送信されない
- API費用が発生しない
- REST APIを提供するので他のアプリと連携できる
2. システム要件
OllamaはCPUだけでも動作するが、GPUがあればはるかに高速だ。
| 項目 | 最小スペック | 推奨スペック |
|---|---|---|
| OS | Windows 10以上 | Windows 11 |
| RAM | 8GB | 16GB以上 |
| GPU | なくても可 | NVIDIA(VRAM 8GB以上) |
| ディスク | 10GB空き容量 | SSD推奨 |
この記事で使用した環境は以下の通りだ。
- CPU: AMD Ryzen 5 7500F
- GPU: NVIDIA RTX 4070(VRAM 12GB)
- RAM: 32GB
- OS: Windows 11 64bit
3. Ollamaのインストール
ollama.com/downloadからWindows用インストーラーをダウンロードする。OllamaSetup.exeを実行すれば、特別な設定なしでインストールが完了する。
インストールが終わったらPowerShellでバージョンを確認する。
ollama --version
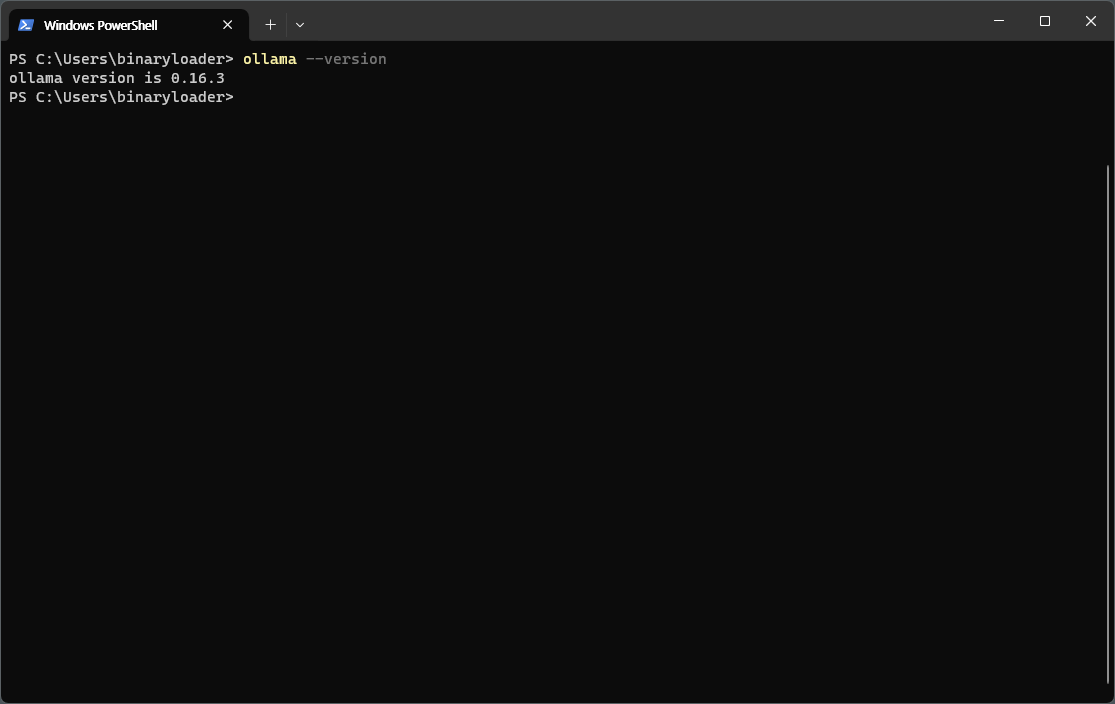
ollama version is 0.16.3のようにバージョンが表示されれば、インストールは正常に完了している。
4. Qwen3:8Bモデルの実行
Qwen3:8BはAlibaba Cloudが公開した80億パラメータモデルだ。韓国語を含む多言語をサポートし、8Bサイズながら優れた性能を持つ。
以下のコマンド1つでモデルのダウンロードと対話型チャットが同時に始まる。
ollama run qwen3:8b
初回実行時はモデルをダウンロードする(約5GB)。ダウンロードが完了すればすぐに会話を始められる。
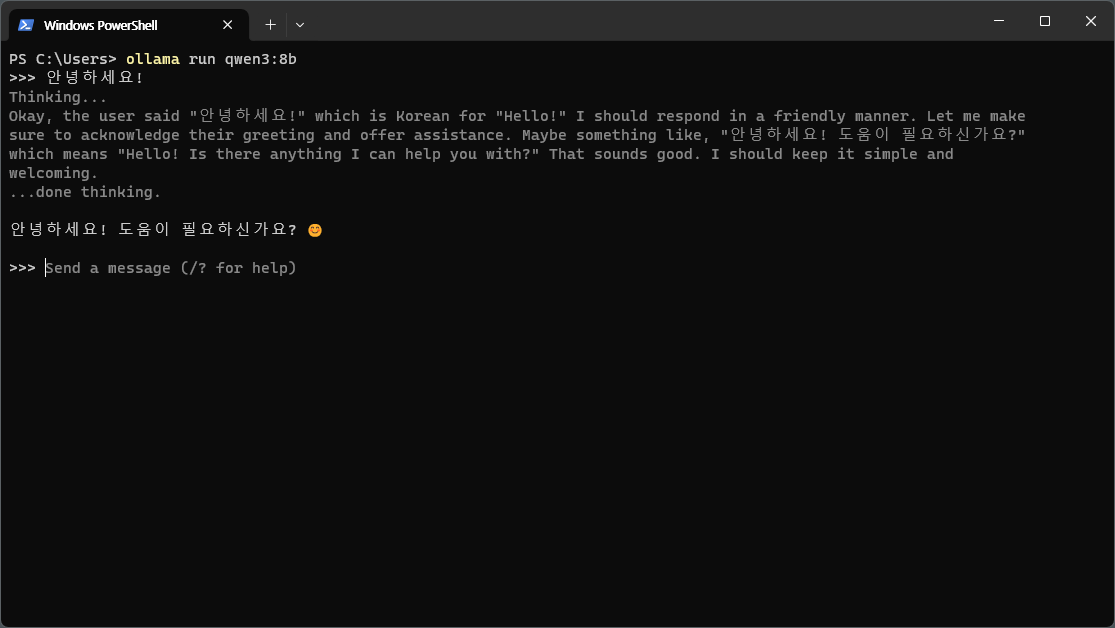
Qwen3はデフォルトでthinkingモードが有効になっているため、Thinking...プロセスを経てから応答する。会話を終了するには/byeと入力する。
5. GPU活用の確認
OllamaはNVIDIA GPUを自動で検出して使用する。nvidia-smiコマンドでVRAM使用量を確認できる。
nvidia-smi
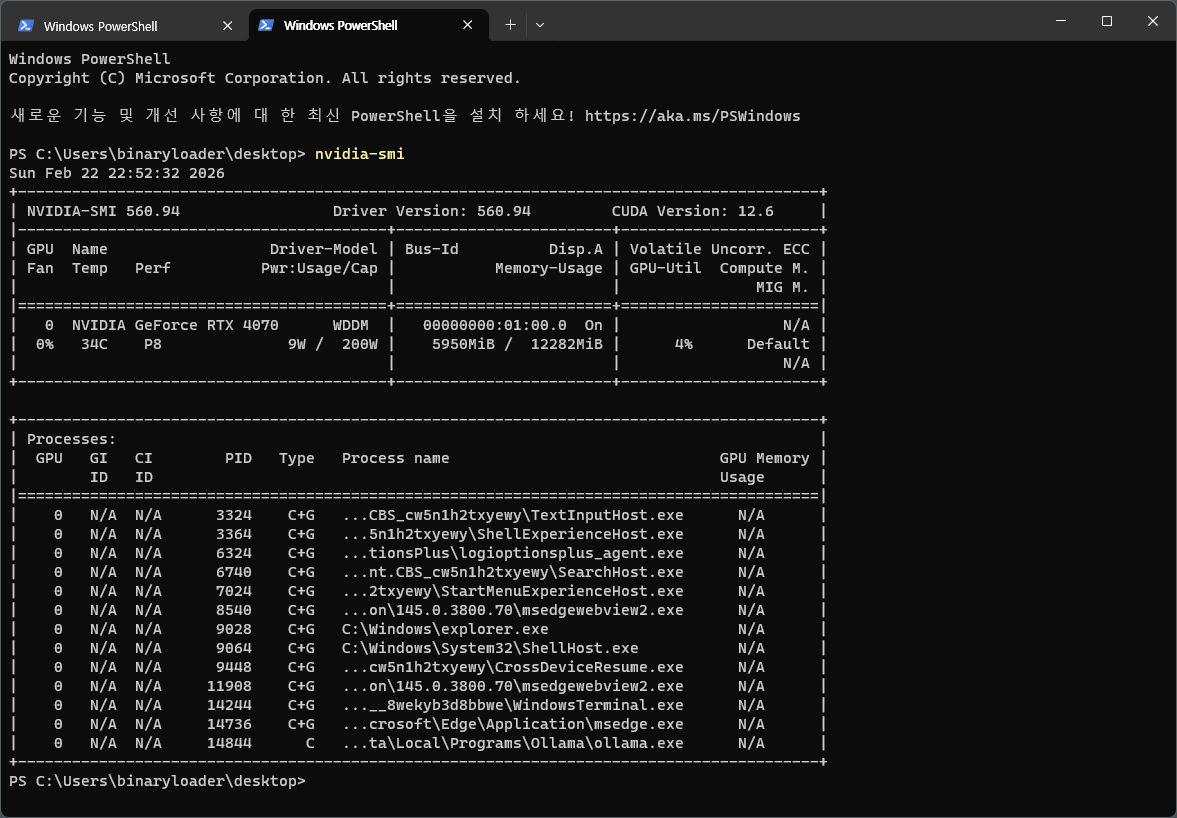
Qwen3:8Bモデルは約6GBのVRAMを使用する。RTX 4070の12GB基準で余裕が十分にある。
6. 基本的な使い方
6.1. 対話型チャット
ollama runコマンドで対話モードに入る。
ollama run qwen3:8b
会話中に使えるコマンドは以下の通りだ。
/bye— 会話終了/clear— 会話履歴のクリア/set parameter temperature 0.7— パラメータ変更
6.2. REST API
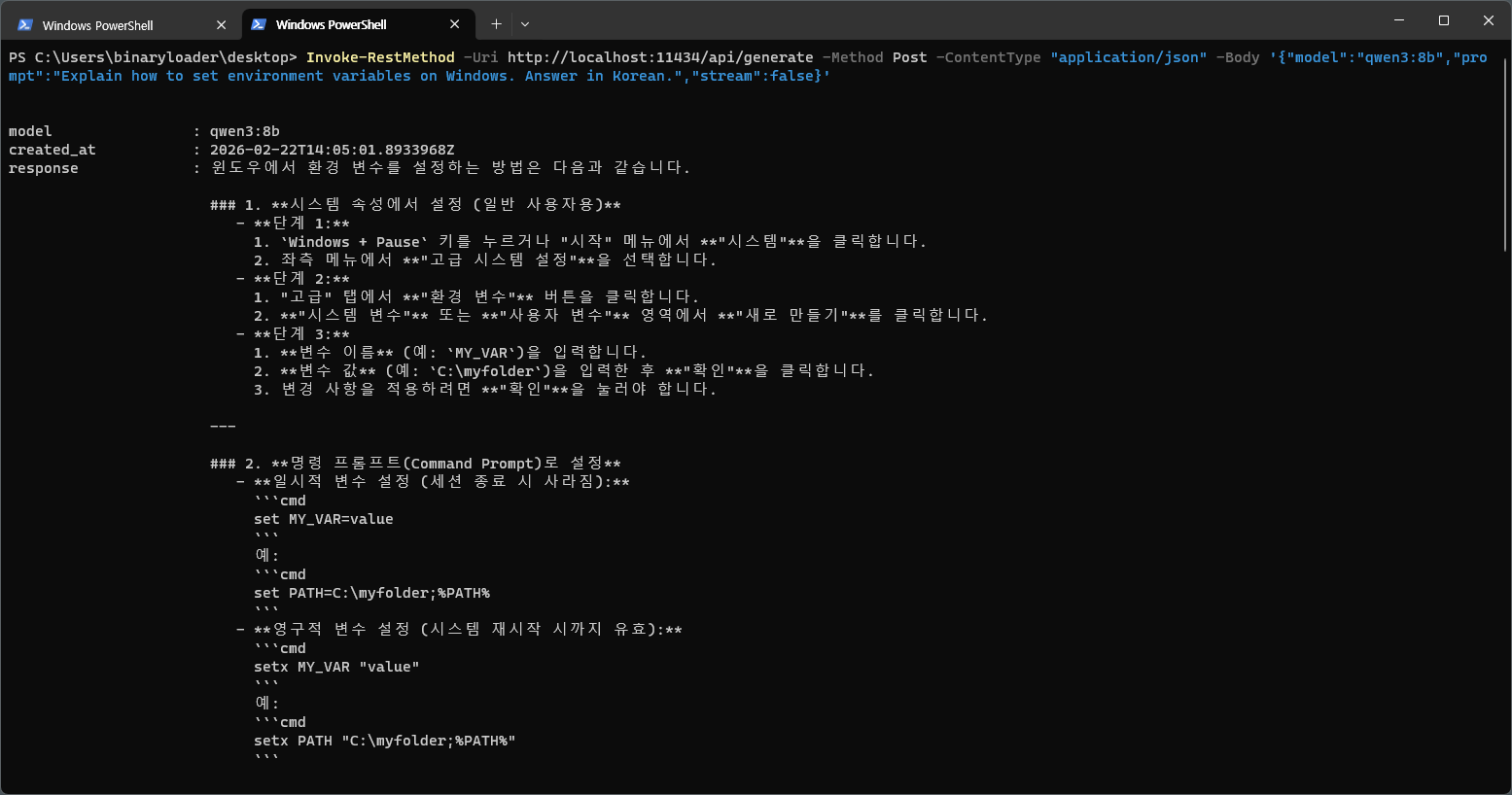
Ollamaはインストールと同時にlocalhost:11434でAPIサーバーを自動的に起動する。他のアプリやスクリプトからすぐに呼び出せる。
$body = '{"model":"qwen3:8b","prompt":"Explain how to set environment variables on Windows. Answer in Japanese.","stream":false}'
Invoke-RestMethod -Uri http://localhost:11434/api/generate -Method Post -ContentType "application/json" -Body $body
7. 便利なコマンド
| コマンド | 説明 |
|---|---|
ollama list |
インストール済みモデル一覧 |
ollama pull qwen3:8b |
モデルダウンロード(実行なし) |
ollama rm qwen3:8b |
モデル削除 |
ollama show qwen3:8b |
モデル詳細情報の確認 |
ollama ps |
実行中のモデル確認 |
ollama stop qwen3:8b |
モデル停止 |



コメントする