
Overview
A breakdown of the architecture and implementation details behind Yangsiljang, a real estate law and precedent RAG chatbot built as a side project. The frontend was built with Claude Code’s help; the backend was written from scratch. Topics covered include a custom Korean tokenizer build for Milvus, Qwen3 embedding/reranker, HyDE, SSE streaming, and data ingestion from the Korean Legislative Service.
Summary
1. How the Side Project Started
Two brothers who share Wook (욱) as a generation character in their given names - both working as developers - put together a team name, WOOKBROS, and have been running side projects together. My younger brother works on AI agents professionally, which means he spends every day working with RAG and LangGraph. Watching from the sideline, I found myself increasingly drawn to the field as the pace of change in LLM agents kept accelerating. The fastest way to learn was to work directly with someone handling it every day, so we decided to build something together. That result is Yangsiljang. For my brother, this was territory that directly overlapped with his daily work, so the implementation itself came quickly and without much friction. The struggle and the wandering were mostly mine.

These books weren’t bought just for this side project. They accumulated one by one as my interest in LLMs and agents deepened. As a mobile developer, all this change brought a quiet unease that even my own area of expertise might end up replaced by agents, and at the same time an academic curiosity grew about how agents actually work on the inside to drive a shift like this. My brother happened to be working in that space every day, so I started adding books out of that curiosity and a desire to learn, and they ended up filling an entire shelf. RAG, LLM fine-tuning, AI agent design, LangChain, embeddings - these topics have become organized enough in the past year to fit inside a single book cover.
The demo video is below.
2. Why We Narrowed the Domain to Real Estate Law and Precedents
The legal domain is a natural fit for RAG. Answers to queries are explicitly present in the text, and the ability to show sources alongside responses makes it possible to suppress hallucination most directly. That said, the legal industry is heavily regulated by licensing requirements, and depending on how you interpret the Attorney-at-Law Act, a chatbot can easily cross from providing simple information into giving legal advice. Even for a side project, this was an area that called for caution.
So we narrowed the domain to laws and precedents related to real estate transactions - purchases, leases, registration, brokerage fees, and pre-sale contracts. These are areas that come up constantly in everyday transactions, and since it’s genuinely hard for non-experts to look up the original statutory text, RAG provides real value here. Every response surfaces the specific statutory provisions and case numbers it drew from, so users can jump straight to the source. Building this myself confirmed that RAG’s hallucination reduction isn’t just about making the model lie less - the real value comes from handing users a direct path to verify the output themselves.
It’s worth spelling out why this matters. The fact that RAG surfaces sources makes model output immediately verifiable. If a user clicks even once on a provision number or case number attached to a response and opens the source text, any misquotation by the model is caught on the spot. That verifiability itself acts as a check on the model. When you instruct the model via system prompt not to answer outside the provided context, and have it cite source metadata directly from the retrieved chunks, the model has less incentive to fabricate content not present in the context. Attempting to suppress hallucination through the model’s internal mechanisms is fundamentally different from building an external verification path - RAG belongs to the latter.
On top of this pipeline, we gave the assistant a persona - Yangsiljang, a veteran in the real estate domain - and the project name stuck.
3. System Architecture
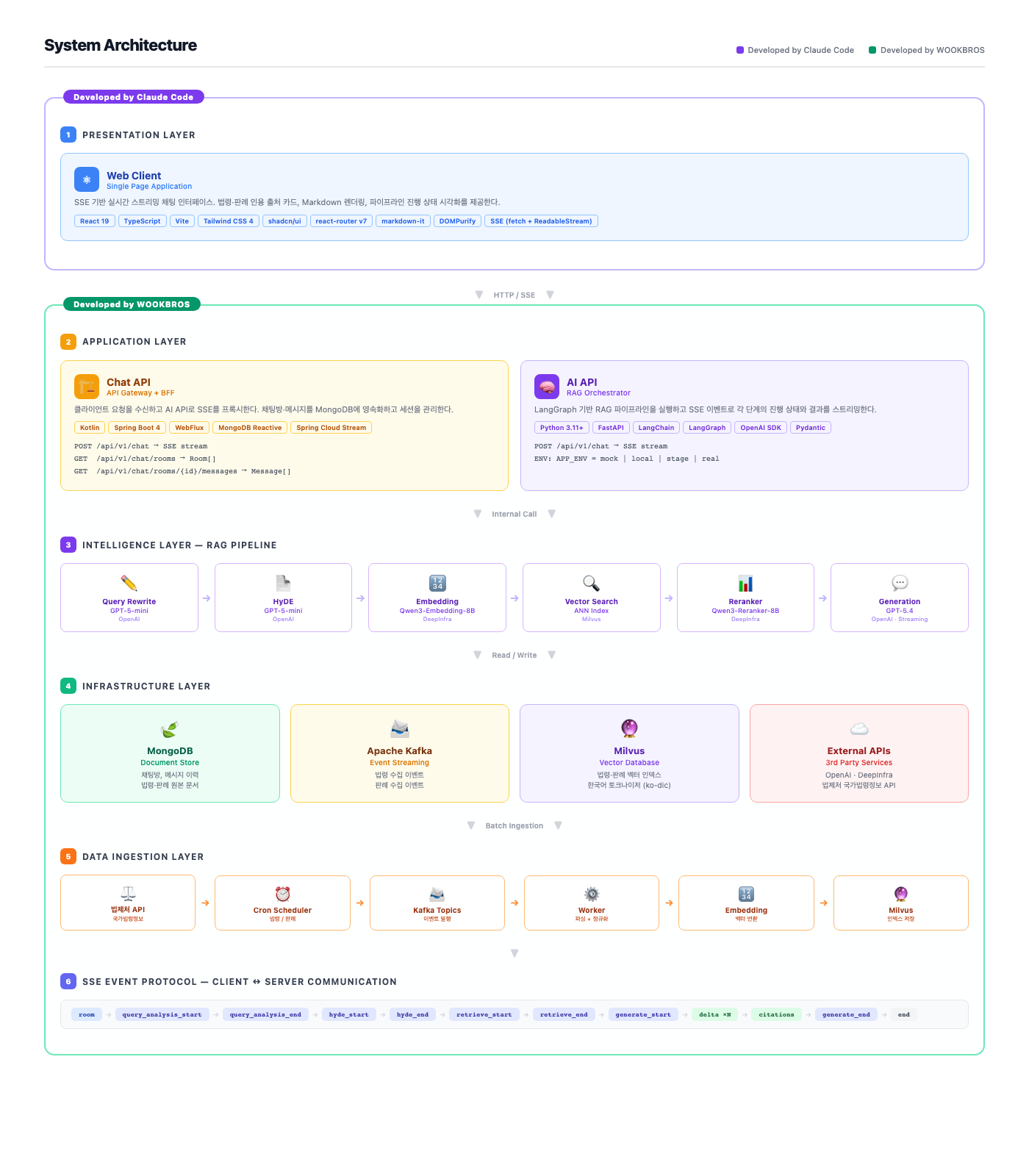
The architecture is divided into six layers, with components and tools described per layer. The two differently colored regions represent different modes of work. The Presentation Layer is where Claude Code’s help was leaned on heavily; everything from the Application layer down through Data Ingestion was written directly. Given limited time in a side project schedule, we chose to invest more in backend design and infrastructure while relying on tooling for the frontend. To be honest, the real deciding factor was something else entirely - I’m a mobile developer, and web frontend is a domain I’ve barely touched. Spending time getting up to speed with a toolchain of React, Vite, Tailwind, and react-router felt like a poor use of hours, so leaning on tooling for unfamiliar territory was the honest call. Claude Code handled the component tree, state management, routing, and styling across a single cycle - I’d hand over the SSE event schema and wireframe intent as prompts, and we’d iterate from there. That said, it wasn’t smooth sailing just because tooling was involved. Because I wasn’t fluent in the domain, reading Claude Code’s output and catching places where it diverged from my intent - then re-directing - involved plenty of flailing. It was faster than doing it myself, but it wasn’t the kind of work where the tool throws a result and you’re done. Working in a domain where I’m weak, that lesson landed clearly again. Within the available hours of a side project, having tooling handle one side while you focus on the other was the right call in hindsight.
4. Presentation Layer - Screens Built with Claude Code
The web client is React 19 + TypeScript + Vite + Tailwind CSS 4 + shadcn/ui + react-router v7. It’s a single-page app that shows the chat room list, message history, and the in-progress response stream all on one screen. Worth noting again that the entire screen was built with Claude Code’s help. Feeding in the SSE event sequence, the screen layout, and the backend OpenAPI schema as prompts, Claude Code would produce a full cycle of component tree, state management, routing, and styling as a draft - and from there I’d catch divergences and re-direct. The parts I directly touched were reviewing and re-directing tool output, fine-tuning design tokens, polishing Korean microcopy, and pinning library versions.
Streaming is handled not through EventSource but via fetch + ReadableStream + TextDecoder, parsing SSE directly. EventSource can’t attach an Authorization header, so for an authenticated chat API, going fetch-based from the start is the obvious choice. The response body is read with getReader() in chunks, decoded from UTF-8 with TextDecoder, and parsed line-by-line into event: and data: fields.
Response markdown is rendered with markdown-it and sanitized with DOMPurify as an extra layer of XSS protection. The assumption is that the model might occasionally output something dangerous like a <script> tag in its markdown, and it’s safer to guard against that. Citation cards are broken out into a separate component that receives the citations event payload (statute name, provision number, case number, source key) and renders them as cards below the answer. Tapping a card jumps to the relevant provision or case page on the Korean Legislative Service (법제처 국가법령정보).
Progress state visualization is also handled at this layer. The query_analysis_start/end, hyde_start/end, retrieve_start/end, and generate_start/end SSE events update a step indicator at the top of the screen. Users can see at a glance which stage their query is sitting in, and the indicator itself has the side effect of teaching users the multi-stage RAG pipeline structure. It was a significantly better UX than hiding everything behind a single loading spinner.
react-router v7 is set up in data router mode. Chat rooms and individual rooms are nested routes, with loaders pulling initial data. The SSE stream doesn’t start inside the loader - it kicks off in a component effect after mount and is torn down via abort controller on unmount. This prevents a previous stream from surviving a fast room switch and continuing to pour tokens into the wrong view.
shadcn/ui works by copying components directly into the codebase, so only selected components were brought in. Dialog, ScrollArea, Tooltip, and Toast were pulled in, with Toast wired to SSE error events to notify users of per-step failures.
5. Application Layer
5.1. Chat API - Kotlin Spring Boot 4 WebFlux
This serves as the chat BFF gateway. It runs on Kotlin + Spring Boot 4 + WebFlux + MongoDB Reactive + Spring Cloud Stream. It receives SSE requests from the client, proxies them to the AI API, and persists chat rooms and messages to MongoDB in between. Being WebFlux-based, SSE backpressure is handled naturally, and a single instance can handle many concurrent streams without breaking a sweat.
The endpoints are straightforward.
POST /api/v1/chat- SSE stream responseGET /api/v1/chat/rooms- user’s chat room listGET /api/v1/chat/rooms/{id}/messages- message history for a specific room
Sessions are stateless; only room and message identifiers are stored in MongoDB. Event streams are piped through WebFlux’s Flux<ServerSentEvent>. Internally, the AI API’s SSE response is consumed via WebClient.get().retrieve().bodyToFlux(ServerSentEvent::class.java), with message persistence injected as a side effect midstream, then forwarded to the client as-is. Token deltas from the AI API pass through unchanged; when a generate_end event arrives, the accumulated response body is saved as a single document in MongoDB. The citations event metadata is stored in the same message document so citation cards can be re-rendered when loading message history later.
The reason for choosing WebFlux is that SSE is inherently a long-lived connection with token-by-token flow. In a Servlet model, each SSE request holds a thread while waiting for tokens, so thread pool exhaustion kicks in fast as concurrent stream count grows. WebFlux’s Reactor-based non-blocking model means the thread isn’t held while a Flux<ServerSentEvent> is flowing.
MongoDB is wired with the Reactive driver. It operates on the same Reactor signal chain as the WebFlux flow, so no blocking call sneaks into the middle.
5.2. AI API - Python FastAPI + LangGraph
The AI orchestrator runs on Python 3.11 + FastAPI + LangChain + LangGraph + OpenAI SDK + Pydantic. LangGraph structures the RAG pipeline as a graph, with each stage emitting start/end events, token deltas, and citation sources as SSE. The same graph definition supports switching behavior via environment variable.
APP_ENV has four modes.
mock- streams fixed responses without any external API calls. Used for frontend development and SSE event sequence validationlocal- calls external LLM/embedding APIs but points to a local Docker Milvus instancestage- staging environment pointing to the real indexreal- production
Mode switching is handled via dependency_overrides, so the same graph definition runs all four modes from one codebase. The embedding client, reranker client, Milvus client, and LLM client are all abstracted behind interfaces, with mode-specific implementations injected. In mock mode, the embedding client returns fixed vectors and the LLM plays back a pre-recorded token sequence. This mock mode makes it possible to lock down SSE event protocol integration tests without any external API dependency.
The LangGraph graph is built with six nodes and edges between them. Node function signatures are state: GraphState -> dict, pulling previous results from state and returning results for the next stage. Each node pushes a *_start event to the SSE queue at the start and a *_end event at the end. This queue flows out as the FastAPI StreamingResponse body. There was a long debate between using LangGraph’s astream_events API versus a custom SSE writer - ultimately, the custom writer won because we needed to enforce our own schema on the SSE payload.
Pydantic models serve as the strict schema for each stage’s SSE payload. Models like QueryAnalysisEnd, HyDEEnd, RetrieveEnd, and Citations each define their data shape, and instances are serialized via model_dump_json() before being sent over SSE. Since both sides of the backend-to-frontend contract are locked to the same schema in code, type mismatches are nearly impossible.
6. Intelligence Layer - 6-Stage RAG Pipeline
The pipeline built in LangGraph is six stages in series. Each stage is one node, and results between nodes flow through channels. For each stage, I’ve noted which model was chosen, why, and how it was tuned.
6.1. Query Rewrite
Sending raw user input directly to the embedding step hurts retrieval quality because of the vocabulary gap between everyday Korean and the formal language of statutory text. GPT-5-mini refines the user’s question into phrasing more likely to match the statutory source. For example, “I can’t get my deposit back” gets rewritten into something containing expressions like “lease deposit return” and “landlord default.” This stage doesn’t need deep reasoning - it’s primarily vocabulary mapping, so a small model is faster and cheaper.
6.2. HyDE - Hypothetical Document Embeddings
When Query Rewrite isn’t enough, HyDE goes one step further. HyDE has the LLM generate a hypothetical answer to the user’s question, then embeds that hypothetical answer for retrieval. Because the embedding is closer in form to an actual answer rather than a question, its cosine similarity to documents containing that answer tends to be higher. In Yangsiljang, GPT-5-mini generates a hypothetical two-paragraph statutory interpretation, which is then embedded. The mechanics are covered in detail in a separate post: [LLM] HyDE - Hypothetical Document Embeddings.
The effect of HyDE was immediately visible in the real estate domain. Comparing raw query embedding against HyDE embedding for the same question, the rank of the correct provision moved up on average - and the gap widened noticeably as user queries got shorter and more colloquial. A single-sentence question like “What do I do if I can’t get my deposit back?” produces an embedding that lacks enough context to land the correct answer inside ANN top-10. After HyDE, the hypothetical answer naturally contains statutory vocabulary like the Housing Lease Protection Act, the right to claim deposit return, and the right of priority reimbursement, pulling the search representation toward the correct chunk.
The cost of HyDE is one additional LLM call. Running both Query Rewrite and HyDE before retrieval means two LLM calls before the search step, which adds latency. To minimize this, both stages are handled by GPT-5-mini with a tight max token budget. The hypothetical answer needs to be around two paragraphs - longer hypotheticals dilute the embedding average and can actually hurt retrieval quality.
For queries outside the real estate domain (for example, “Who is Yangsiljang?”), the HyDE node is bypassed via a conditional edge. The Query Rewrite node’s output JSON includes a domain_match: bool flag, which LangGraph’s conditional edge uses to route off-domain queries to a short path that politely generates a refusal response.
6.3. Embedding - Qwen3-Embedding-8B
The embedding model is Qwen3-Embedding-8B, hosted on DeepInfra. The reasoning was that Korean embedding quality is strong, and DeepInfra serves the Qwen3 family through a standard OpenAI-compatible API without requiring a dedicated GPU - a good fit for a side project’s cost curve.
One more reason for choosing DeepInfra: being able to get both the Qwen3 embedding and reranker from a single provider was a meaningful operational simplification. One key, one billing account, one compatible API schema handles both models.
6.4. Vector Search - Milvus ANN Index
The vector database is Milvus. Retrieval runs as a BM25 + ANN hybrid search. In statutory text, exact matches on provision numbers and defined terms can be decisive, and BM25 catches those matches that ANN alone would miss.
6.5. Reranker - Qwen3-Reranker-8B
ANN search results are not fed directly into the context - they go through a reranker first. Real estate statutes often use similar words with different meanings (e.g., landlord vs. tenant, ownership right vs. right of use), and cosine similarity alone can push the correct provision toward the back. The reranker scores query-candidate pairs directly, catching these semantic collisions.
The reranker of choice is Qwen3-Reranker-8B. It showed stable performance in the Korean legal domain compared to other candidates, and the fact that it belongs to the same Qwen3 family as the embedding model also influenced the decision. Because both models share the same backbone, their representation spaces are similar - meaning the reranker re-examining candidates selected by the embedding model produces less representational mismatch.
6.6. Generation - GPT-5.4 Streaming
Final answer generation uses GPT-5.4 via OpenAI Streaming. The system prompt encodes the persona (Yangsiljang, veteran real estate expert), the response format (summary - evidence - citation), and a rule prohibiting reasoning outside the provided context. A delta SSE event is sent with each token as it flows, and citation source metadata extracted during retrieval is sent all at once as a citations event immediately after generation completes. Context is assembled by appending the reranker’s top chunks after the system prompt as user-turn content, with source labels explicitly prefixed before each chunk so the model can weave citation labels naturally into its response.
7. Data Ingestion Layer - Korean Legislative Service to Kafka to Milvus
Statutory and precedent source text is fetched from the Korean Legislative Service (법제처) Open API. The team maintains a separate Open Law API documentation reference, so endpoint and parameter matrices were pulled from there directly.
The ingestion pipeline runs as Cron Scheduler -> Kafka topic -> Worker -> Embedding -> Milvus ingest.
- The Cron Scheduler calls the Korean Legislative Service API on a set update cycle
- Ingestion results are published as events to a Kafka topic, keeping ingestion asynchronous from the RAG pipeline
- Workers consume events from Kafka and perform source text parsing, normalization, and chunking
- Chunk-level text is sent to the embedding model to produce vectors. The same model used at ingest time must be used at query time to keep representation spaces aligned
- Embedding results are loaded into Milvus. Source chunks are simultaneously stored in MongoDB so the original text can be displayed verbatim when cited in a response
Chunking strategy varies by content type. Statutes are split at the provision level, since provisions are natural semantic units; provisions that are too long are split further at the clause or sub-clause level. Precedents have a defined document structure (ruling matters, summary of decision, reasoning, disposition), which is preserved as the basis for semantic chunking.
The reason for including Kafka is that ingestion needed to be completely asynchronous from the RAG pipeline. User chat cannot pause while new statutes are being ingested, and ingestion failures must resolve as indexing failures - not propagate as chat failures. Kafka acts as the safety belt between the two domains.
8. Milvus Korean Tokenizer - Custom Build with lindera-ko-dic
This section is where the most time was lost in the entire Yangsiljang project. Milvus full-text search runs on Tantivy, and Tantivy’s tokenizer supports Japanese dictionaries (IPADIC, UniDic) and Korean dictionary (ko-dic) via Lindera. The problem is that the official Milvus Docker image only includes the Japanese dictionary build. Feeding Korean text into the default image breaks BM25 matching into single-character units, making the hybrid full-text search essentially useless.
The solution was to build Milvus directly with the Korean dictionary. A feat/ko-dic-build branch was cut from the Milvus fork and a Dockerfile.ko-dic was added. The core is a single build argument line.
ARG TANTIVY_FEATURES=lindera-ko-dic
RUN make milvus TANTIVY_FEATURES=${TANTIVY_FEATURES}
The milvusdb/milvus-env:ubuntu22.04-... image is used as the builder, compiling with TANTIVY_FEATURES=lindera-ko-dic baked in. The output (*.so + Go binary) is copied into a second-stage ubuntu:jammy base, with LD_LIBRARY_PATH=/milvus/lib and LD_PRELOAD=/milvus/lib/libjemalloc.so set to produce the final production image.
With this custom build, specifying ko-dic as the text_analyzer enables Korean morpheme-level tokenization. BM25 + ANN hybrid search accuracy in Korean came back to life.
9. SSE Event Protocol
The SSE event sequence between the client and AI API is diagrammed at the bottom of the architecture overview.
room
→ query_analysis_start → query_analysis_end
→ hyde_start → hyde_end
→ retrieve_start → retrieve_end
→ generate_start → delta×N → citations → generate_end
→ end
Each event is one SSE event: type, and the data: payload differs per stage. query_analysis_end carries the rewritten query; hyde_end carries the hypothetical answer; retrieve_end carries retrieved chunk info; delta carries a token fragment; citations carries citation metadata (statute name, provision number, case number, source key).
The end event is an explicit stream termination signal. In standard SSE, clients learn of termination when the server closes the connection, but having an explicit termination event makes it easy to distinguish clean termination from unexpected disconnection.
10. Deployment - My Brother’s Territory
The AWS deployment side isn’t covered in depth here. Infrastructure is defined in Terraform on top of EKS, which my brother handled directly - it’s not territory I know well, so those details are deferred to a future cycle. We briefly looked at container image building, ECR upload, and per-environment config injection together, but cluster topology, IAM policies, and similar areas were handed off entirely. To be honest, by the time we’d burned through all our hours on the RAG pipeline internals, the ambition to dive deep into infra just wasn’t there.
11. What We Learned - and What’s Missing
Working on Yangsiljang as a side project substantially changed my impression of RAG. RAG is not simply a pattern that stitches search and generation together - it’s an integrated pipeline where index quality, tokenizer, embedding, reranker, context assembly, and source exposure all have to fit together for results to come out. Building it at the code level made that clear. Any weak link immediately degrades answer quality, and that weakness is surfaced directly to the user in the form of citation output. The virtue of RAG in showing sources to reduce hallucination is simultaneously a mirror that exposes the system’s own weak points without mercy.
We started in a narrow domain - real estate - but I got a feel for how the same pipeline could transfer directly to other licensed industries like healthcare, tax, or insurance. The parts that only require swapping out domain vocabulary were larger than expected, and it seems the core assets concentrate in three things: morpheme-level tokenizer + embedding/reranker combination + citable data source.
On the other hand, there are clearly areas that typical agents cover which Yangsiljang doesn’t. Dynamic tool selection (automatically choosing external tools based on the query), context compression (reducing tokens while preserving meaning across long conversations), multi-turn memory management, and self-critique didn’t get touched in v1 scope. My brother was busy with his day job, so the side project cadence was uneven, and time concentrated first on the RAG pipeline, Korean tokenizer, and index quality - all higher priorities. Moving toward a fuller agent feature set is deferred to the next cycle.
Pushing through this cycle took a non-trivial amount of time. For nearly two months, whenever the work stretched on, I was glued to the side project and study sessions well into the night. Wrapping up the full day’s work at the day job and only starting late in the evening - one failed Korean tokenizer build costs a few hours to rebuild, one round of embedding/reranker comparison burns another few hours. The study was pulled along by two things at once - an anxiety that even my own area of expertise might end up replaced by agents, and an academic curiosity about how agents actually work on the inside - but once I was inside it, the interest was genuine enough that staying glued to it late into the night never wore me down. The side project acted as a learning accelerator.
One step further and there’s room to build something that actually automates or assists with real estate transaction workflows. But to get there, you’d need to know how licensed real estate agents operate - where the friction is, where the time drains. I don’t have that domain intuition. I’ve never run a real estate transaction myself, so it’s hard to know which features are missing and which automations are worth building. Getting RAG to handle statutory search was about as far as we could reach without domain knowledge. Beyond that is territory this side project couldn’t touch.
In the end, the thought that domain expertise is the core came back clearly. An AI agent - even with model, pipeline, and infrastructure all in place - produces features that deliver false utility to users if the problem being solved isn’t precisely defined. Choosing which embedding model to use is a smaller decision than figuring out which specific user behavior to reduce and how. What we were able to do with Yangsiljang was take the RAG stack all the way through one full cycle. To turn it into a real product, a domain expert needs to come in and point to where it actually hurts. We confirmed that in reverse.
The Yangsiljang side project wraps up here for now. Nearly two months of late evenings stretching on, energy and momentum both running dry at the end - but the primary goal of driving one full cycle of the RAG pipeline was met. The next cycle will start somewhere else. The weight of domain expertise that Yangsiljang taught us will carry directly into how the next project is chosen.
One last thing: the experience of building this with my brother was the biggest takeaway. When you’re pairing with someone who works with RAG and LangGraph every day professionally, details that a book couldn’t show you arrive all at once. Because of him, a book’s worth of study compressed into a few weeknight pairing sessions. From embedding model selection to chunking strategy, reranker evaluation, LangGraph node design, and SSE event protocol design - what works and what breaks in practice was something I could absorb by being right there. The lightweight format of a side project made it possible to dive in without pressure on a weekday evening, and it ended up being the period when I moved through the steepest part of the learning curve at the fastest speed.
References
Owners:
- Planning
- binaryloader
- Research
- binaryloader
- Drafting
- binaryloader
- Editing
- binaryloader
- Review
- binaryloader
- Translation
- Claude
- Thumbnail
- Claude
- Publishing
- Claude



Leave a comment