
概要
サイドプロジェクトとして開発した不動産法令・判例RAGチャットボット「ヤン室長(양실장)」のアーキテクチャと実装の詳細をまとめる。フロントエンドはClaude Codeの力を借りて構築し、バックエンドは自力で実装した。Milvus韓国語トークナイザーのカスタムビルド、Qwen3埋め込み/リランカー、HyDE、SSEストリーミング、韓国法制処データのインジェストまでを扱う。
まとめ
1. サイドプロジェクトの始まり
名前に「ウク(욱)」という通字を共有している二人の兄弟がたまたまどちらも開発者として働いていたので、WOOKBROSというチーム名をつけてサイドプロジェクトをいくつか一緒に回している。弟は現職でAIエージェントを開発しており、RAGとLangGraphを毎日触る立場にある。それを隣で見ていると、LLMエージェント領域の変化の幅があまりにも大きく、自分も急速に興味が湧いてきた。最も早い学習経路は、現職でそれを毎日扱っている弟から教わることだった。一緒に作ってみようと決めた結果が、ヤン室長だ。弟にとっては会社で毎日扱う資産がそのまま活きる領域だったので、実装自体は速くて難しくない立場だった。苦労と迷走の時間はほぼ自分の取り分だった。

上の書籍はこのサイドプロジェクトのためだけに買ったわけではなく、LLMとエージェント領域への関心が深まるにつれて一冊ずつ手元に集めてきたものだ。モバイル開発者として腰を据えて働いてきた立場から、変化の波の前に自分の専門領域までエージェントに置き換えられるのではという漠然とした不安が頭をよぎり、同時にエージェントが内側で実際にどう動いてこの流れを作っているのかという学術的な好奇心も深まっていった。ちょうど弟がその領域を毎日扱う立場にいたので、勉強を兼ねて一冊ずつ加えていたら一列になった。RAG、LLMファインチューニング、AIエージェント設計、LangChain、埋め込みといった領域が、ここ1年の間に書籍一冊にまとまるほど整理されてきたということでもある。
デモ動画は以下のとおりだ。
2. ドメインを不動産法令・判例に絞った理由
法律ドメイン自体はRAGがよく機能する領域だ。質問への回答がテキストの中に明示的に埋め込まれており、出典を一緒に示せるという点で、幻覚リスクを最も直接的に抑えることができる。ただし法律産業はライセンス規制が厳しい領域で、弁護士法の解釈次第ではチャットボットが単純な情報提供を超えて法的助言とみなされる余地がある。サイドプロジェクトとはいえ、この点は慎重にならざるを得なかった。
そこで扱えるドメインを不動産取引に関連する法令と判例に絞った。売買、賃貸借、登記、仲介手数料、分譲といった日常の取引でよく直面する領域で、非専門家が直接法令原文を調べることが難しいという点でRAGの効用が大きい。回答には常に引用した法令条項と判例番号を一緒に表示し、ユーザーが原文にすぐジャンプできるようにした。RAGが誇る幻覚の低減は、単にモデルが嘘をつかなくなるということではなく、ユーザーに直接検証経路を手渡すところに本当の価値があるということを、実際に作りながら確認した。
この幻覚低減の原理はもう少し掘り下げておく価値がある。RAGが出典を表示するという事実は、モデルの出力を即座に検証可能な形にする。回答の横に付いた条項番号や判例番号をユーザーが一度でもクリックして原文を開けば、モデルが誤引用していた場合はその場で露見する。この検証可能性それ自体が、モデルに対する一種の牽制装置となる。システムプロンプトでコンテキスト外の情報で回答しないというルールを埋め込み、コンテキストとして入力されたチャンクの出典メタデータをそのまま引用させれば、モデルはコンテキストにない内容を作り出す動機が薄れる。モデル内部のメカニズムで幻覚を抑えようとするアプローチと、システム外部に検証経路を作って抑えるアプローチは本質的に異なり、RAGは後者に属する。
この経路の上にアシスタントのペルソナを不動産領域のベテランのようなヤン室長として設定し、プロジェクト名もそのままヤン室長になった。
3. システムアーキテクチャ
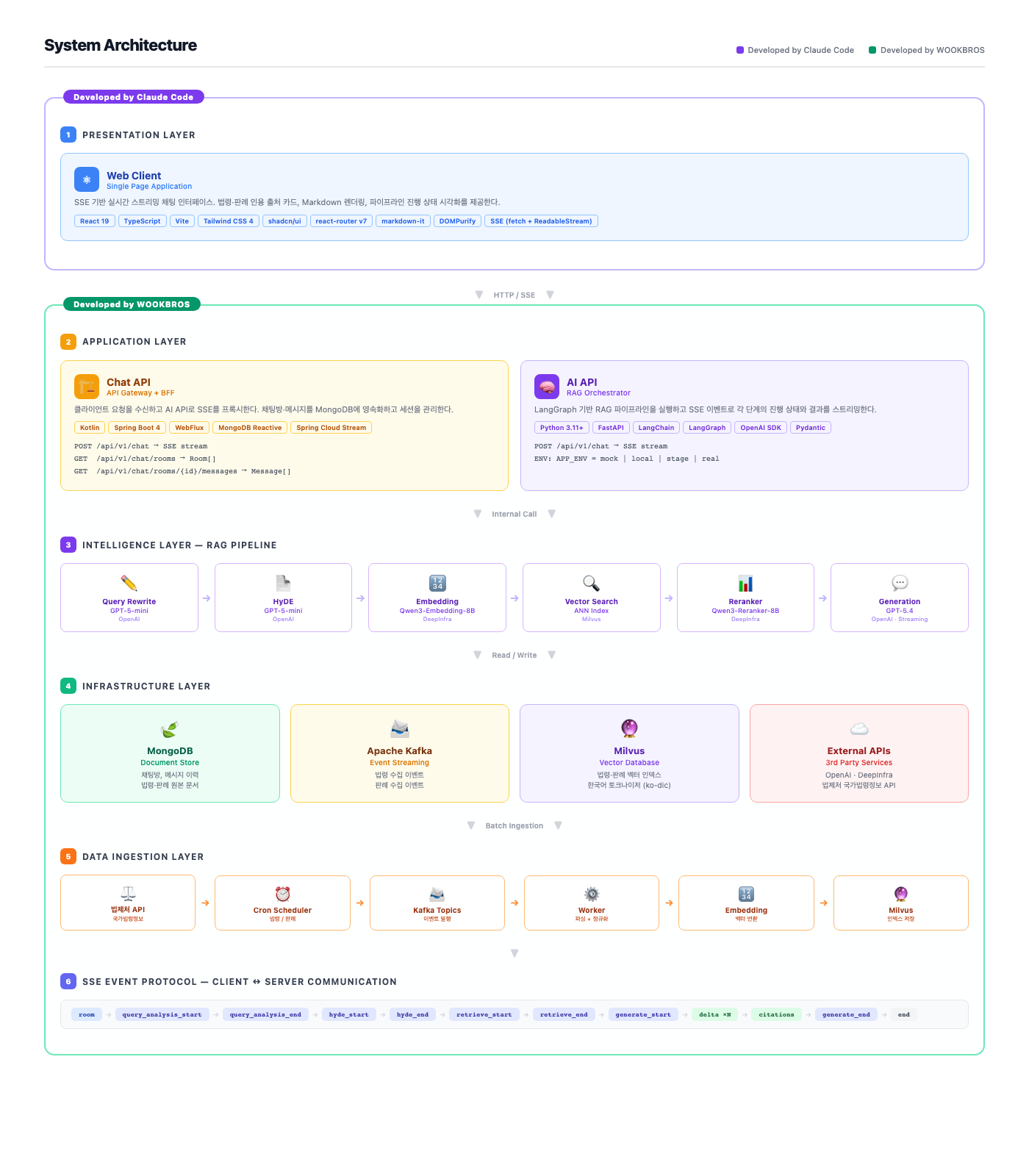
レイヤーを6つに分け、各レイヤーの中でどんなコンポーネントとツールを使ったかをまとめる。色が異なる二つの領域は作業方式の分離を示している。Presentation LayerはClaude Codeの力を大きく借りた領域で、ApplicationからData Ingestionまでは自分で書いた領域だ。サイドプロジェクトのスケジュールで時間が限られているため、バックエンドの設計とインフラに時間を多く投資し、フロントはツールの手を積極的に借りる方向を選んだ。正直に言えば、決定的な理由は別にあった。自分はモバイル開発者なので、Webフロントエンドはほとんど触ったことがない領域だ。React、Vite、Tailwind、react-routerといったツールチェーンの中で手をほぐすために時間を消費するより、慣れていない立場はツールの助けを借りて進める方が正直な判断だった。画面構成、コンポーネント分割、ルーティング、スタイルをClaude Codeと一緒に作り、SSEイベントのスキーマとワイヤーフレームの意図をプロンプトとして整理してやり取りする形で進めた。ただし、ツールの手を借りたからといって作業がスムーズだったわけではない。自分がよく知らない領域なので、Claude Codeが出した結果を読み、意図とずれている部分を見つけてまた指示し直す過程でかなりの試行錯誤があった。自分で書くよりは速かったが、ツールが結果を出したらそのまま終わりという作業でもなかったという点は、弱い領域で作業している間に改めて確認した。サイドプロジェクトの限られた時間の中でフルスタックを回すなら、片方にツールの助けを積極的に借りる決断は、結果的に正しかった。
4. Presentation Layer - Claude Codeと一緒に作った画面
Webクライアントの構成はReact 19 + TypeScript + Vite + Tailwind CSS 4 + shadcn/ui + react-router v7だ。シングルページアプリとして、チャットルームリスト、メッセージ履歴、進行中の応答ストリームを一画面で表示する。この画面全体がClaude Codeの力を借りて作られた領域であることをもう一度書き添えておく。SSEイベントのシーケンス、画面構成案、バックエンドのOpenAPIスキーマをプロンプトとして渡すと、Claude Codeがコンポーネントツリー、状態管理、ルーティング、スタイルの初稿を一サイクルで展開してくれ、その上で意図とずれた部分を見つけてまた指示するという形で回した。人が直接入った部分はツール出力のレビューと再指示、デザイントークンの微調整、韓国語マイクロコピーの調整、ライブラリバージョンのピン留め程度だった。
ストリーミングはEventSourceではなく、fetch + ReadableStream + TextDecoderの組み合わせで直接SSEを処理する。EventSourceはAuthorizationヘッダーを付けられないという制限があるため、認証付きチャットAPIでは最初からfetchベースで進むのが一般的な選択肢だ。fetchのレスポンスボディをgetReader()でチャンク単位に読み、TextDecoderでUTF-8デコードした後、event:/data:行単位で直接パースする。
応答マークダウンはmarkdown-itでレンダリングし、DOMPurifyでXSSをもう一段防ぐ。モデルがたまたま<script>のような危険要素を含むマークダウンを流してくる可能性を想定して対策しておく方が安全だ。引用出典カードは別コンポーネントとして切り出し、citationsイベントのペイロード(法令名、条項番号、判例番号、原文キー)を受け取ってカード形式で回答の下に展開する。カードをタップすると韓国の国家法令情報(법제처 국가법령정보)の該当条項や判例ページにジャンプする。
進行状況の可視化もこのレイヤーの役割だ。SSEのquery_analysis_start/end、hyde_start/end、retrieve_start/end、generate_start/endイベントを受け取り、画面上部のステップインジケーターを更新する。ユーザーは自分の質問がどのステップで処理されているかを視覚的にすぐ確認でき、この進行表示自体がRAGの多段パイプラインをユーザーに教える効果もある。単純なローディングスピナー一つで隠すよりはるかに優れたUXだった。
react-router v7はdata routerモードで導入した。チャットルームリストと個別チャットルームをネストされたルートとして設定し、loaderで初期データを取得する。SSEストリームはloaderの中で開始せず、コンポーネントマウント後のeffectで開始し、unmount時にabort controllerで切断する。チャットルームを素早く切り替えた際に前のストリームが生き残ってトークンを吐き続けるという事故を防ぐためだ。
shadcn/uiはコンポーネントをコードベースに直接コピーする方式なので、必要なコンポーネントだけを選んで取り込んだ。Dialog、ScrollArea、Tooltip、Toastを取り込み、ToastはSSEのエラーイベントと連携してユーザーにステップ単位の失敗を通知する。
5. Application Layer
5.1. Chat API - Kotlin Spring Boot 4 WebFlux
チャットBFFゲートウェイの役割を担う。Kotlin + Spring Boot 4 + WebFlux + MongoDB Reactive + Spring Cloud Streamで動く。クライアントのSSEリクエストを受けてAI APIにプロキシし、その間にチャットルームとメッセージをMongoDBに永続化する。WebFluxベースなのでSSEのバックプレッシャーが自然に支えられ、1インスタンスで多数の同時ストリームを軽く処理できる。
エンドポイントはシンプルだ。
POST /api/v1/chat- SSEストリームレスポンスGET /api/v1/chat/rooms- ユーザーのチャットルーム一覧GET /api/v1/chat/rooms/{id}/messages- 特定ルームのメッセージ履歴
セッション自体はステートレスに保ち、ルーム/メッセージの識別子だけをMongoDBに持つ。WebFluxのFlux<ServerSentEvent>でイベントストリームをそのまま流す。内部実装はAI APIのSSEレスポンスをWebClient.get().retrieve().bodyToFlux(ServerSentEvent::class.java)で受け取り、パイプラインの途中でメッセージ永続化の副作用を挟み、そのままクライアントに流す形だ。AI APIから来るトークンデルタはそのままパススルーし、generate_endイベントが届いた瞬間に蓄積した回答本文を一塊としてMongoDBに保存する。citationsイベントのメタデータも同じメッセージドキュメントに一緒に保存し、後でメッセージ履歴を読み込む際に出典カードを再描画できるようにした。
WebFluxを選んだ理由はSSEが本質的にlong-lived connectionであり、トークン単位で流れるからだ。Servletモデルでは一つのリクエストが一つのスレッドを占有したままトークンを待ち続けるため、同時ストリーム数が増えるほどスレッドプールが急速に枯渇する。WebFluxはReactorベースのノンブロッキングモデルなので、Flux<ServerSentEvent>が流れている間もスレッドを占有しない。
MongoDBはReactiveドライバーで接続した。WebFluxの流れと同じReactorシグナルの上で動くため、途中にブロッキング呼び出しが入り込まない。
5.2. AI API - Python FastAPI + LangGraph
AIオーケストレーターはPython 3.11 + FastAPI + LangChain + LangGraph + OpenAI SDK + Pydanticで構成される。LangGraphでRAGパイプラインをグラフとして組み立て、各ステップの開始/終了イベント、トークンデルタ、引用出典をSSEで流す。同じグラフ定義の上で環境変数で動作モードを切り替えられるようにした。
APP_ENVは4段階に分けた。
mock- 外部API呼び出しなしで固定レスポンスを流すモード。フロントエンド開発とSSEイベントシーケンスの検証用local- ローカルで外部LLM/埋め込みAPIだけを呼び出し、ベクターDBはDockerのMilvusを参照するstage- ステージング環境。実際のインデックスを参照するreal- 本番
モード分岐はdependency_overridesで処理し、同じグラフ定義が4つのモードを一つのコードベースで全て動かす。埋め込みクライアント、リランカークライアント、Milvusクライアント、LLMクライアントはすべてインターフェースで抽象化されており、モードごとに異なる実装が注入される。mockモードでは埋め込みが固定ベクターを返し、LLMが事前に録音したトークンシーケンスを流す。このmockモードのおかげで、SSEイベントプロトコルの統合テストを外部API依存なしに確実に固定できる。
LangGraphのグラフは6ノードとその間のエッジで構成される。ノード関数のシグネチャはstate: GraphState -> dictで、前のステップの結果をstateから取り出し、次のステップが使う結果を返す。各ノードは開始時点で*_startイベントを、終了時点で*_endイベントをSSEキューにpushする。このキューはFastAPIのStreamingResponseのボディとして流れ出る。LangGraphのastream_events APIと自作のSSEライターのどちらに統一するかしばらく悩んだが、SSEペイロードを自分たちのスキーマで強制するために独自ライターを置く方向に落ち着いた。
Pydanticモデルは各ステップのSSEペイロードスキーマを強固に固定する役割を果たす。QueryAnalysisEnd、HyDEEnd、RetrieveEnd、Citationsといったモデルがそれぞれのデータ形状を定義し、model_dump_json()でシリアライズしてSSEに乗せて送る。バックエンドとフロントエンドの間の契約をコードの両側が同じスキーマで固定しているので、型がずれることはほぼない。
6. Intelligence Layer - RAGパイプライン6段階
LangGraphで組んだパイプラインは直列6段階だ。各段階が一つのノードで、ノード間の結果はチャンネルで流れる。各段階でどのモデルを選び、なぜ選び、どのようにチューニングしたかをまとめる。
6.1. Query Rewrite
ユーザー入力をそのまま埋め込みに送ると、日常的な韓国語と法令原文の語彙の差によって検索品質が落ちる。GPT-5-miniでユーザーの質問を法令で使われそうな表現に一度整える。例えば「保証金が返ってこない」のような入力は「賃貸借保証金の返還、賃貸人の債務不履行」といった表現が入った形に書き直される。このステップは深い推論を必要とせず、語彙マッピングが主体なので小さいモデルの方が速くてコストが低い。
6.2. HyDE - Hypothetical Document Embeddings
Query Rewriteだけでは不十分なときにもう一段入り込む。HyDEはユーザーの質問に対する仮想回答をLLMが一度生成し、その仮想回答を埋め込んで検索に使う手法だ。質問の埋め込みではなく回答に近い形の埋め込みが作られるため、同じ回答を含む実際の文書とのコサイン類似度が高くなる。ヤン室長ではGPT-5-miniで仮想の法令解説回答を2段落ほど生成し、その結果を埋め込む。詳しい原理は別の記事[LLM] HyDE - Hypothetical Document Embeddingsで扱った。
不動産ドメインではHyDEの効果が即座に見えた。同じ質問でrawクエリの埋め込みとHyDE埋め込みで検索した場合、正解条項のランクが平均的に上がり、特にユーザーの質問が短く日常語であるほど差が広がった。一行の質問(例:「保証金が返ってこなかったらどうすればいいですか?」)は埋め込み自体のコンテキストが不足しているためANN top-10に正解が入らないケースが多いが、HyDEを通すと仮想回答の中に住宅賃貸借保護法、保証金返還請求権、優先弁済権といった法令語彙が自然に登場し、検索表現が正解チャンク側に引き寄せられる。
HyDEの代償は呼び出しが一回追加されることだ。Query Rewriteの後にHyDEも行うと、検索前のLLM呼び出しが2回になり、その分応答時間が増える。このコストを抑えるために両ステップをGPT-5-miniで束ね、最大トークン数を短く設定して応答遅延を抑える。仮想回答は2段落程度で十分で、それ以上長くなると埋め込みの平均が薄れてかえって検索品質が落ちる。
不動産ドメイン外の一般的な質問が来た場合(例:「ヤン室長って誰ですか?」)はHyDEノードをスキップするよう分岐を設けた。Query Rewriteノードの出力JSONにdomain_match: boolフラグを入れ、LangGraphの条件エッジでHyDEをバイパスする経路に送る。ドメイン外の質問はそのまま丁重な拒否回答を生成する短い経路で終わる。
6.3. Embedding - Qwen3-Embedding-8B
埋め込みモデルはQwen3-Embedding-8BをDeepInfraのホスティングで使った。韓国語の埋め込み品質が高いという判断で、DeepInfraは専用GPUなしでもQwen3ファミリーを標準のOpenAI互換APIで提供してくれるためサイドプロジェクトのコスト曲線に合っていた。
DeepInfraを選んだ理由をもう一つ挙げると、Qwen3ファミリーの埋め込みとリランカーを同じプロバイダー一社から受けられるという運用上のシンプルさが大きかった。キー一式、請求一件、互換APIスキーマ一つで両モデルを扱える。
6.4. Vector Search - Milvus ANN Index
ベクターDBはMilvusだ。検索はBM25 + ANNのハイブリッドで動かす。法令条項は条項番号や定義語彙が完全一致する場合にBM25が決定打になることがあり、ANNだけでは捉えられないマッチングをBM25が補完した。
6.5. Reranker - Qwen3-Reranker-8B
ANN検索結果をそのままコンテキストとして使わず、リランカーで再ランク付けする。不動産法令では似た単語が異なる意味で使われるケースが多く(例:賃貸 vs 賃借、所有権 vs 使用権)、ANNのコサイン類似度だけでは正解条項が後ろに押しやられることがあった。リランカーはクエリと候補のペアを直接採点するため、こういった意味的な衝突を捉えられる。
リランカーはQwen3-Reranker-8Bを選んだ。韓国語法律ドメインで他の候補と比較して安定していると判断し、埋め込みと同じQwen3ファミリーで動くという点も決定に影響した。両モデルが同じバックボーンから派生しているため表現空間が近く、埋め込みが選んだ候補をリランカーが再評価する際の表現ずれが少ない。
6.6. Generation - GPT-5.4 Streaming
最終的な回答生成はGPT-5.4をOpenAI Streamingで受け取る。システムプロンプトにペルソナ(不動産ベテランのヤン室長)、回答形式(要約→根拠→引用)、そしてコンテキスト外の推論禁止ルールを埋め込む。トークンが流れるたびにSSEでdeltaイベントを送り、検索ステップで抽出した引用出典メタデータは回答生成が終わった直後にcitationsイベントとして一括送信する。コンテキストはリランカーが選んだチャンクをシステムプロンプトの後にuserメッセージとして付け加え、モデルが出典ラベルを回答の中に自然に組み込めるようチャンクの前に出典ラベルを明示的に記載する。
7. Data Ingestion Layer - 法制処からKafkaへ、MilvusへImport
法令と判例の原文は韓国法制処(법제처)の国家法令情報Open APIから取得する。チームで別途まとめておいたOpen Law APIドキュメントがあるので、エンドポイントとパラメーターのマトリクスはそちらで確認した。
収集パイプラインはCronスケジューラー → Kafkaトピック → Worker → 埋め込み → Milvusインジェストの順だ。
- Cronスケジューラーが更新周期に合わせて韓国法制処APIを呼び出す
- 収集結果はKafkaトピックにイベントとして発行する。インジェストがRAGパイプラインと非同期で流れるよう分離した箇所だ
- WorkerがKafkaからイベントをコンシューマーとして受け取り、原文パースと正規化、チャンキングを行う
- チャンク単位のテキストを埋め込みモデルに送ってベクターを生成する。検索時にも同じモデルを使わなければ表現空間がずれる
- 埋め込み結果をMilvusに投入する。同時に原文チャンクをMongoDBにも保存し、回答引用時に原本テキストをそのまま表示できるようにする
チャンキング戦略は内容の種類ごとに変えた。法令は条項が自然な意味単位なので条項単位で区切り、長すぎる条項は項・号単位でもう一段細かく切る。判例は判決文の構造(判示事項、判決要旨、理由、主文)が決まっているので、その構造を活かして意味単位でチャンキングした。
Kafkaをあえて挟んだ理由は、インジェストがRAGパイプラインと完全に非同期である必要があったからだ。新しい法令が入っている間もユーザーのチャットが止まってはならないし、インジェストの失敗はインデクシング失敗で終わらなければならず、チャット失敗に波及してはいけない。Kafkaが二つの領域の間の安全弁として機能する。
8. Milvus 韓国語トークナイザー - lindera-ko-dicカスタムビルド
この節がヤン室長で最も時間を取られた箇所だ。Milvusのフルテキスト検索はTantivyの上で動き、TantivyのトークナイザーはLinderaを通じて日本語辞書(IPADIC、UniDic)や韓国語辞書(ko-dic)を使える。問題はMilvusの公式Dockerイメージが日本語辞書ビルドしか含まないという点だ。韓国語をそのまま入力するとBM25マッチングが1文字単位で壊れ、フルテキストハイブリッド検索が事実上無意味になった。
解決策はMilvusを韓国語辞書で直接ビルドすることだった。milvusのフォークにfeat/ko-dic-buildブランチを切り、Dockerfile.ko-dicを追加した。核心はビルド引数の一行だ。
ARG TANTIVY_FEATURES=lindera-ko-dic
RUN make milvus TANTIVY_FEATURES=${TANTIVY_FEATURES}
milvusdb/milvus-env:ubuntu22.04-...イメージをビルダーとして使い、TANTIVY_FEATURES=lindera-ko-dicを埋め込んでコンパイルする。成果物(*.so + Goバイナリ)を第二ステージのubuntu:jammyにコピーし、LD_LIBRARY_PATH=/milvus/libとLD_PRELOAD=/milvus/lib/libjemalloc.soも設定して本番イメージを焼く。
このようにビルドしたイメージでtext_analyzerにko-dicを指定すると、韓国語形態素単位のトークナイズが動作する。BM25 + ANNハイブリッド検索における韓国語の精度が復活した。
9. SSEイベントプロトコル
クライアントとAI APIの間のSSEイベントシーケンスは、アーキテクチャ図の一番下の行にそのまま描かれている。
room
→ query_analysis_start → query_analysis_end
→ hyde_start → hyde_end
→ retrieve_start → retrieve_end
→ generate_start → delta×N → citations → generate_end
→ end
各イベントが一つのSSE event:タイプで、data:ペイロードはステップごとに異なる。query_analysis_endには書き直されたクエリ、hyde_endには仮想回答、retrieve_endには検索されたチャンク情報、deltaにはトークンの断片、citationsには引用メタデータ(法令名、条項番号、判例番号、原文キー)が入る。
endイベントは明示的なストリーム終了シグナルだ。一般的なSSEではサーバーが接続を閉じることでクライアントが終了を認識するが、明示的な終了イベントがあると正常終了と異常終了を区別しやすい。
10. デプロイ - 弟が担当した領域
AWSデプロイの領域はこの記事では深く扱わない。TerraformでEKSの上にインフラを定義して立ち上げる形で弟が直接担当した領域で、自分はよく知らない立場なので詳細は次のサイクルに持ち越した。コンテナイメージのビルドとECRへのアップロード、環境別の設定注入くらいは一緒に軽く見たが、クラスタートポロジーやIAMポリシーといった領域は弟の手に全部委ねた。RAGパイプラインの内側に時間を全部使った後、インフラまで深く見ようという欲が出なかったというのが正直なところでもある。
11. 何を学んだか - そして何が足りないか
サイドプロジェクトとしてヤン室長を回しながら、RAGに対する印象がかなり変わった。RAGは単に検索と生成を組み合わせるパターンではなく、インデックス品質、トークナイザー、埋め込み、リランカー、コンテキスト構成、出典表示といった領域がすべて一本に繋がって初めて結果が出る統合パイプラインだということを、コードレベルで直接触りながら確認した。一箇所でも弱ければ回答品質が即座に落ち、その弱さは引用出典の形でユーザーにそのまま露出される。幻覚を減らすために出典を表示するRAGの美徳は、同時にシステム自体の弱い部分をそのまま映し出す鏡でもあった。
不動産という狭いドメインから始めたが、同じパイプラインが医療、税務、保険といった他のライセンス産業にもそのまま移行できるという感覚を掴んだ。ドメイン語彙を入れ替えるだけでよい部分が意外と大きく、核心的な資産は形態素単位のトークナイザー + 埋め込み/リランカーの組み合わせ + 引用可能なデータソースの三つに集まっているようだ。
一方で、一般的なエージェントが提供する機能の中でヤン室長が埋められていない領域も明らかにある。動的ツール選択(質問に合った外部ツールを自動選択)、コンテキスト圧縮(長い会話で意味を保存しながらトークンを減らす)、マルチターンメモリ管理、自己検証(self-critique)といった機能はv1のスコープでは手をつけられなかった。弟が本業で忙しくサイドプロジェクトのペースが安定しなかったこともあり、優先度の高いRAGパイプラインと韓国語トークナイザー、インデックス品質の方に時間が先に集中した。一般的なエージェントの機能セットへ一段進む作業は次のサイクルに持ち越している。
このサイクルを押し進めるのに費やした時間もかなりのものだった。ほぼ2ヶ月近く、作業が長引いた日には夜遅くまでサイドプロジェクトと勉強に張り付いた。本業の一日を終えた遅い夜から始めて、韓国語トークナイザーのビルドが一度失敗すると再ビルドに数時間かかり、埋め込み/リランカーの比較を一ラウンド回すとまた数時間が消えるという繰り返しだった。自分の専門領域までエージェントに置き換えられるのではという不安と、エージェントが内側で実際にどう動いているのかという学術的な好奇心が一緒に引っ張ってきた勉強だったが、実際に入ってみると遅くまで張り付いても疲れが残らないほど興味が伴ってきた。サイドプロジェクトが一つの学習加速装置として機能した時間だった。
一歩さらに進めば、不動産取引そのもののワークフローを自動化したり補助する機能まで作れるはずだった。宅地建物取引業者がどうやって物件登録、契約書作成、権利関係の確認、相場分析、顧客対応といった業務を回しているのかを知り、その流れの中でどこに摩擦があってどこに時間が漏れているかを把握しなければ、本当に役に立つエージェントは作れない。ただ、自分にはそのドメインの現場感覚がない。不動産取引を自分で実際に経験したことがないので、どの機能が足りなくてどの自動化が必要かを見極めることが難しかった。RAGで法令検索を解決するところまでがドメイン知識なしでも辿り着ける場所で、その先はこのサイドプロジェクトの手が届かない領域だった。
結局、ドメインが核心だという考えが改めて明確になった。AIエージェントはモデル、パイプライン、インフラがすべて揃っていても、解こうとしている問題が正確に定義されていなければ、その上で作った機能はユーザーに偽の効用を与える水準で止まる。どの埋め込みモデルを選ぶかより、ユーザーのどの行動をどう減らしてあげるかの方が大きな決断だ。ヤン室長で自分たちにできたのはRAG技術スタックを最後まで一サイクル回してみることで、本当の製品として持っていくにはドメインの専門家が入って痛い箇所を指摘してくれる必要があるということを、逆向きに確認した格好だ。
ヤン室長のサイドプロジェクトはここで一段落とする。2ヶ月近く遅い時間まで張り付き、体力もペースも一度底をついた時期だったが、RAGパイプラインを丸ごと一サイクル回してみるという第一目標は十分達成できたと思う。次のサイクルはここで止まり、別の領域に移る予定だ。ヤン室長で学んだドメインの重みは、次のプロジェクトを選ぶ基準にそのまま反映されそうだ。
最後に、弟と一緒に作った経験自体が最大の収穫だった。現職でRAGとLangGraphを毎日扱う人と隣り合ってペアを組んでいると、本を読んでは見えなかったディテールが一度に入ってくる。弟のおかげで書籍一冊分の勉強が、平日夜のペア数回に圧縮されて入ってきた。埋め込みモデルの選択からチャンキング戦略、リランカーの評価方法、LangGraphのノード設計、SSEイベントプロトコルの設計まで、実戦でどの判断が機能してどの判断が崩れるかを隣で吸収することができた。このサイドプロジェクトの軽いフォーマットが平日の夜でも気軽に取り組める環境を作り、結果として学習曲線が最も急な区間を最も速いスピードで通過した時期になった。
参考
担当者:
- 企画
- binaryloader
- リサーチ
- binaryloader
- 下書き
- binaryloader
- 編集
- binaryloader
- レビュー
- binaryloader
- 翻訳
- Claude
- サムネイル
- Claude
- 公開
- Claude



コメントする