
개요
사이드 프로젝트로 진행한 부동산 법령·판례 RAG 챗봇 양실장의 아키텍처와 구현 디테일을 정리한다. 프론트엔드는 Claude Code의 도움을 받아 짜고 백엔드는 직접 구현했다. Milvus 한국어 토크나이저 커스텀 빌드, Qwen3 임베딩/리랭커, HyDE, SSE 스트리밍, 법제처 데이터 인제스트까지 다룬다.
정리
1. 사이드 프로젝트의 시작
이름에 욱이라는 돌림자를 쓰고 있는 두 형제가 마침 둘 다 개발자로 일하고 있는 김에 WOOKBROS라는 팀명을 붙이고 사이드 프로젝트들을 같이 굴리고 있다. 동생은 현업에서 AI 에이전트를 개발하고 있어서 RAG와 LangGraph를 매일 만지는 자리에 있다. 옆에서 보고 있자니 LLM 에이전트 영역의 변화 폭이 너무 커서 나도 급격히 관심이 생겼고 가장 빠른 학습 경로는 현업에서 직접 다루는 동생에게 배우는 것이었다. 같이 만들어 보기로 한 결과물이 양실장이다. 동생에게는 회사에서 매일 다루는 자산이 그대로 적용되는 영역이라 구현 자체는 빠르고 어렵지 않은 자리였고 어려움과 헤매는 시간은 거의 내 몫이었다.

위 책들은 이번 사이드 프로젝트만을 위해 산 것은 아니고 LLM과 에이전트 영역에 관심이 깊어지면서 한 권씩 들여 모은 것들이다. 모바일 개발자로 자리잡고 일해온 입장에서 변화의 파도 앞에 내 전문 영역까지 에이전트로 대체되는 게 아닐까 하는 불안감이 슬쩍 들었고 동시에 에이전트가 안에서 어떻게 동작하길래 이런 흐름이 만들어지는지에 대한 학술적 궁금함도 함께 깊어졌다. 마침 동생이 그 영역을 매일 다루는 자리에 있어서 공부 겸 한 권씩 더하다 보니 한 줄이 만들어졌다. RAG, LLM 파인튜닝, AI 에이전트 설계, 랭체인, 임베딩 같은 영역이 최근 1년 사이에 책 한 권으로 묶일 만큼 정리된 셈이다.
데모 영상은 아래와 같다.
2. 도메인을 부동산 법령·판례로 좁힌 이유
법률 도메인 자체는 RAG가 잘 동작하는 영역이다. 질의에 대한 답이 텍스트 안에 명시적으로 박혀 있고 출처를 함께 보여줄 수 있다는 점에서 환각 위험을 가장 직접적으로 누를 수 있다. 구현 자체는 법제처 API에서 가져올 수 있는 모든 법령과 판례를 인덱싱해 두었지만 라이선스 규제가 강한 영역이라 일반 법률 전반을 그대로 노출하는 부분은 조심스러웠다. 그래서 도메인을 부동산 쪽으로만 동작하도록 제약을 걸어 두었다. 인덱스와 파이프라인 자체는 다 만들어 두고 도메인 게이트로 좁히는 식이다.
다룰 수 있는 도메인을 부동산 거래 관련 법령과 판례로 좁힌 결과는 아래와 같다. 매매, 임대차, 등기, 중개수수료, 분양 같은 일상 거래에서 자주 부딪히는 영역이고 비전문가가 직접 법령 원문을 찾기 어렵다는 점에서 RAG의 효용이 크다. 응답에는 항상 인용한 법령 조항과 판례 번호를 함께 노출해 사용자가 원문으로 바로 점프할 수 있게 했다. RAG가 자랑하는 환각 감소는 단순히 모델이 거짓말을 덜 하는 차원이 아니라 사용자에게 직접 검증 경로를 쥐어 주는 데서 진짜 가치가 나온다는 것을 직접 만들어 보면서 확인했다.
이 환각 감소 원리는 한 번 더 짚어둘 가치가 있다. RAG가 출처를 노출한다는 사실은 모델 출력을 곧바로 검증 가능한 형태로 만든다. 답변 옆에 붙은 조항 번호와 판례 번호를 사용자가 한 번이라도 클릭해서 원문을 열어 보면 모델이 잘못 인용한 경우는 그 자리에서 들통난다. 이 검증 가능성 자체가 모델에게도 일종의 견제 장치가 된다. 시스템 프롬프트에서 컨텍스트 외 정보로 답변하지 말라는 규칙을 박아두고 컨텍스트로 들어온 청크의 출처 메타데이터를 그대로 인용하게 하면 모델은 컨텍스트 안에 없는 내용을 만들어낼 동기가 줄어든다. 환각을 모델 내부 메커니즘으로 누르려는 시도와 시스템 외부에서 검증 경로를 만들어 누르는 시도는 본질적으로 다른 접근이고 RAG는 후자에 속한다.
이 경로 위에 어시스턴트의 페르소나를 부동산 영역의 베테랑 같은 양실장으로 잡았고 프로젝트 이름도 그대로 양실장이 되었다.
3. 시스템 아키텍처
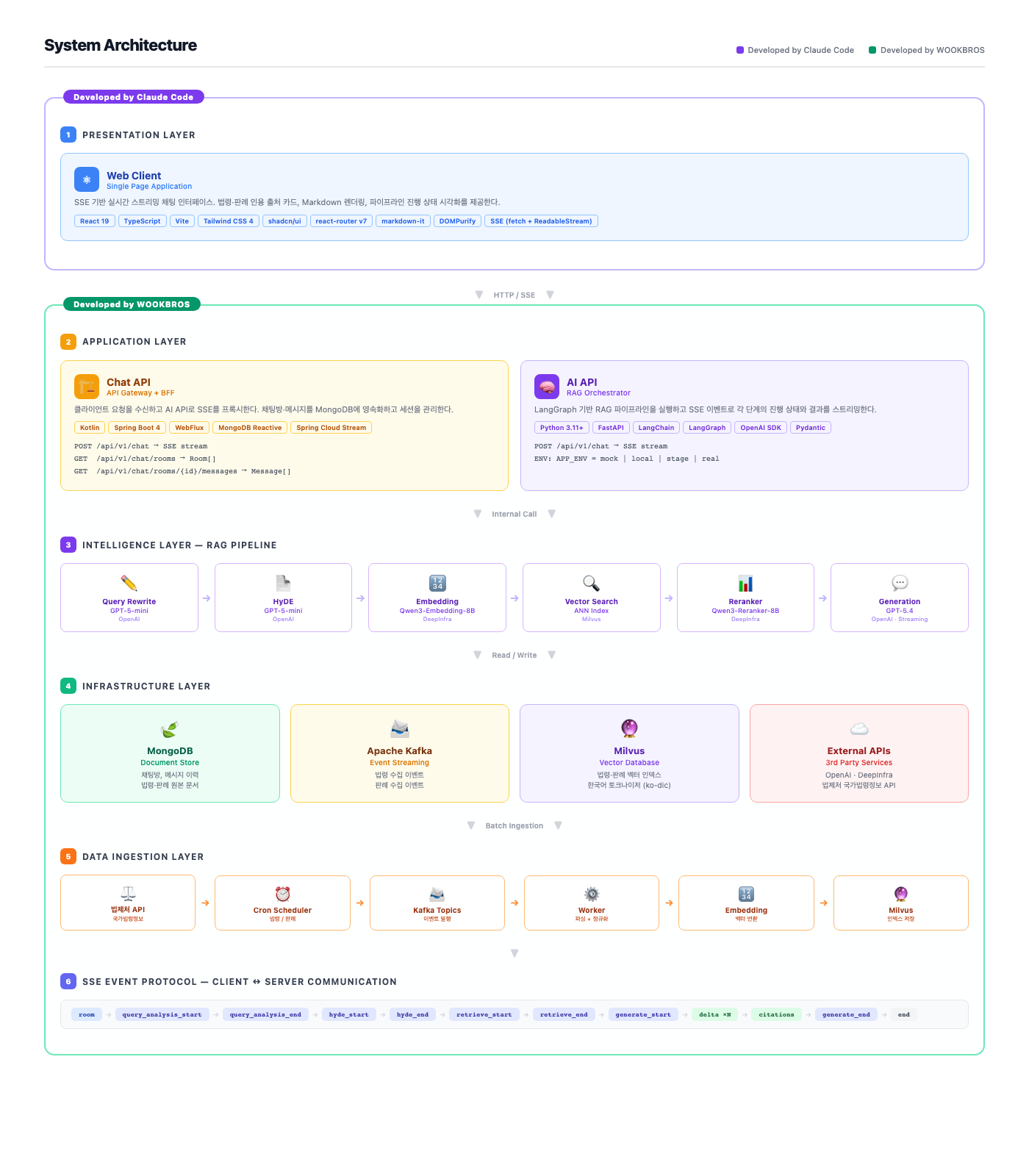
레이어를 6개로 나누고 각 레이어 안에서 어떤 컴포넌트와 도구를 썼는지 따로 정리한다. 색이 다른 두 영역은 작업 방식 분리다. Presentation Layer는 Claude Code의 도움을 크게 받아 굴린 영역이고 Application부터 Data Ingestion까지는 직접 짠 영역이다. 사이드 프로젝트 일정에서 시간이 한정되어 있다 보니 백엔드 설계와 인프라에 시간을 더 투자하고 프론트는 도구의 손을 적극적으로 빌리는 방향을 택했다. 솔직히 말하면 결정적인 이유는 따로 있었다. 본인은 모바일 개발자라 웹 프론트엔드는 거의 다뤄본 적이 없는 영역이다. React, Vite, Tailwind, react-router 같은 도구 체인 안에서 손을 푸느라 시간을 태우기보다 익숙하지 않은 자리는 도구의 도움을 받아 굴리는 쪽이 정직했다. 화면 구성, 컴포넌트 분리, 라우팅, 스타일을 Claude Code와 함께 짰고 SSE 이벤트 스키마와 와이어프레임 의도를 프롬프트로 정리해 주고받는 식으로 진행했다. 다만 도구의 손을 빌렸다고 해서 작업이 매끄러웠던 것은 아니다. 본인이 잘 모르는 영역이다 보니 Claude Code가 내놓은 결과를 읽고 의도와 어긋나는 부분을 잡아 다시 지시하는 과정에서 삽질이 적지 않았다. 직접 짜는 것보다 빠르긴 했지만 도구가 결과를 던진다고 그대로 끝나는 작업은 아니었다는 점은 본인의 약한 영역에서 일하는 동안 한 번 더 확인했다. 사이드 프로젝트의 가용 시간 안에서 풀스택을 굴리려면 한쪽에 도구의 도움을 적극적으로 받는 결정이 결과적으로 옳았다.
4. Presentation Layer - Claude Code와 함께 짠 화면
웹 클라이언트는 React 19 + TypeScript + Vite + Tailwind CSS 4 + shadcn/ui + react-router v7 조합이다. 단일 페이지 앱으로 채팅방 목록, 메시지 이력, 진행 중인 응답 스트림을 한 화면에서 보여준다. 이 화면 전체가 Claude Code의 도움을 받아 짜인 영역이라는 점을 한 번 더 적어둔다. 프롬프트로 SSE 이벤트 시퀀스, 화면 구성안, 그리고 백엔드 OpenAPI 스키마를 던져주면 Claude Code가 컴포넌트 트리, 상태 관리, 라우팅, 스타일의 초안을 한 사이클로 펼쳐주고 그 위에서 의도와 어긋난 부분을 잡아 다시 지시하는 식으로 굴렀다. 사람이 직접 들어간 부분은 도구 출력 검수와 재지시, 디자인 토큰 미세 조정, 한국어 마이크로카피 다듬기, 라이브러리 버전 핀 정도였다.
스트리밍은 EventSource가 아니라 fetch + ReadableStream + TextDecoder 조합으로 직접 SSE를 처리한다. EventSource가 Authorization 헤더를 못 붙이는 한계 때문에 인증 채팅 API에서는 처음부터 fetch 기반으로 가는 게 일반적인 선택지다. fetch 응답 본문을 getReader()로 받아 청크 단위로 읽고 TextDecoder로 utf-8 디코딩한 뒤 event:/data: 라인 단위로 직접 파싱한다.
응답 마크다운은 markdown-it로 렌더링하고 DOMPurify로 XSS를 한 단계 더 막는다. 모델이 어쩌다 <script> 같은 위험 요소를 포함한 마크다운을 흘려보낼 가능성을 가정하고 가는 것이 안전하다. 인용 출처 카드는 별도 컴포넌트로 떼어놓고 citations 이벤트의 페이로드(법령명, 조항 번호, 판례 번호, 원문 키)를 받아 카드 형태로 답변 아래에 펼쳐 놓는다. 카드를 누르면 법제처 국가법령정보의 해당 조항이나 판례 페이지로 점프한다.
진행 상태 시각화도 이 레이어의 몫이다. SSE의 query_analysis_start/end, hyde_start/end, retrieve_start/end, generate_start/end 이벤트를 받아 화면 상단의 단계 인디케이터를 갱신한다. 사용자는 자기 질문이 어느 단계에서 머무르고 있는지 시각적으로 바로 알 수 있고 이 진행 표시 자체가 RAG의 다단계 파이프라인을 사용자에게 학습시키는 효과도 있다. 단순한 로딩 스피너 한 개로 가리는 것보다 훨씬 나은 UX였다.
react-router v7은 data router 모드로 깔았다. 채팅방 목록과 개별 채팅방을 nested route로 잡고 loader로 초기 데이터를 가져온다. SSE 스트림은 loader 안에서 시작하지 않고 컴포넌트 마운트 후 effect로 시작해 unmount 시 abort controller로 끊어버린다. 채팅방을 빠르게 전환할 때 이전 스트림이 살아남아 토큰을 토해내는 사고를 막기 위해서다.
shadcn/ui는 컴포넌트를 직접 코드베이스에 복사해 두는 방식이라 특정 컴포넌트만 골라서 가져온다. Dialog, ScrollArea, Tooltip, Toast 정도를 가져왔고 Toast는 SSE 에러 이벤트와 연결해 사용자에게 단계 단위 실패를 알려준다.
5. Application Layer
5.1. Chat API - Kotlin Spring Boot 4 WebFlux
채팅 BFF 게이트웨이 역할이다. Kotlin + Spring Boot 4 + WebFlux + MongoDB Reactive + Spring Cloud Stream 위에서 돈다. 클라이언트의 SSE 요청을 받아 AI API로 프록시하고 그 사이에 채팅방, 메시지를 MongoDB에 영속화한다. WebFlux 기반이라 SSE 백프레셔가 자연스럽게 받쳐주고 한 인스턴스에서 다수의 동시 스트림을 가볍게 받을 수 있다.
엔드포인트는 단순하다.
POST /api/v1/chat- SSE 스트림 응답GET /api/v1/chat/rooms- 사용자 채팅방 목록GET /api/v1/chat/rooms/{id}/messages- 특정 방의 메시지 이력
세션 자체는 stateless로 두고 방/메시지 식별자만 MongoDB에 들고 있는다. WebFlux의 Flux<ServerSentEvent>로 이벤트 스트림을 그대로 흘려준다. 내부 구현은 AI API의 SSE 응답을 WebClient.get().retrieve().bodyToFlux(ServerSentEvent::class.java)로 받아 파이프라인 중간에서 메시지 영속화 부수 효과를 끼워 넣고 그대로 클라이언트로 흘려보내는 형태다. AI API에서 들어오는 토큰 델타는 그대로 패스스루하고 generate_end 이벤트가 도착하는 순간 누적된 답변 본문을 한 덩어리로 MongoDB에 저장한다. citations 이벤트의 메타데이터도 같은 메시지 도큐먼트에 함께 저장해서 나중에 메시지 이력을 불러올 때 출처 카드를 다시 그릴 수 있게 했다.
WebFlux를 고른 이유는 SSE가 본질적으로 long-lived connection이고 토큰 단위로 흐르기 때문이다. Servlet 모델에서 SSE를 받으면 한 요청이 한 스레드를 점유한 채 토큰이 오기를 기다리게 되므로 동시 스트림 수가 늘어날수록 스레드 풀이 빠르게 고갈된다. WebFlux는 Reactor 기반 non-blocking 모델이라 Flux<ServerSentEvent>가 흘러가는 동안 스레드를 점유하지 않는다.
MongoDB는 Reactive 드라이버로 붙였다. WebFlux 흐름과 같은 Reactor 시그널 위에서 동작하기 때문에 중간에 blocking 호출이 끼어들지 않는다.
5.2. AI API - Python FastAPI + LangGraph
AI 오케스트레이터는 Python 3.11 + FastAPI + LangChain + LangGraph + OpenAI SDK + Pydantic 조합이다. LangGraph로 RAG 파이프라인을 그래프로 구성해 각 단계의 시작/종료 이벤트, 토큰 델타, 인용 출처를 SSE로 흘려보낸다. 같은 그래프 정의 위에서 환경 변수로 동작 모드를 바꿀 수 있게 했다.
APP_ENV는 네 단계로 나눴다.
mock- 외부 API 없이 고정 응답을 흘려보내는 모드. 프론트 개발과 SSE 이벤트 시퀀스 검증용local- 로컬에서 외부 LLM/임베딩만 호출하고 벡터 DB는 도커 Milvus를 본다stage- 스테이지 환경. 실제 인덱스를 본다real- 운영
모드 분기는 dependency_overrides로 처리해서 같은 그래프 정의가 4개 모드를 한 코드 베이스에서 다 돌린다. 임베딩 클라이언트, 리랭커 클라이언트, Milvus 클라이언트, LLM 클라이언트가 모두 인터페이스로 추상화돼 있고 모드별로 다른 구현이 주입된다. mock 모드에서는 임베딩이 고정 벡터를 돌려주고 LLM이 사전에 녹음해둔 토큰 시퀀스를 흘려보낸다. 이 mock 모드 덕분에 SSE 이벤트 프로토콜의 통합 테스트를 외부 API 의존 없이 단단히 잠가둘 수 있다.
LangGraph 그래프는 6개 노드와 그 사이 엣지로 구성된다. 노드 함수의 시그니처는 state: GraphState -> dict로 이전 단계 결과를 state에서 꺼내고 다음 단계가 쓸 결과를 반환한다. 각 노드는 시작 시점에 *_start 이벤트를, 종료 시점에 *_end 이벤트를 SSE 큐에 push한다. 이 큐는 FastAPI의 StreamingResponse 본문으로 흘러나간다. LangGraph의 astream_events API와 직접 만든 SSE writer 사이에서 어떤 쪽으로 통일할지 한참 고민했는데 결국 SSE 페이로드를 우리 쪽 스키마로 강제하기 위해 직접 writer를 두는 쪽으로 갔다.
Pydantic 모델은 SSE 페이로드의 단계별 스키마를 강하게 잠그는 역할을 한다. QueryAnalysisEnd, HyDEEnd, RetrieveEnd, Citations 같은 모델이 각각의 데이터 모양을 정의하고 모델 인스턴스를 model_dump_json()으로 직렬화해 SSE에 실어 보낸다. 백엔드와 프론트 사이의 계약을 코드 양쪽이 같은 스키마로 잡고 있으므로 타입이 어긋날 일이 거의 없다.
6. Intelligence Layer - RAG 파이프라인 6단계
LangGraph로 짠 파이프라인은 직렬 6단계다. 각 단계가 하나의 노드이고 노드 간 결과는 채널로 흐른다. 각 단계별로 어떤 모델을 골랐고 왜 골랐고 어떻게 튜닝했는지 따로 정리한다.
6.1. Query Rewrite
사용자 입력을 그대로 임베딩으로 보내면 일상 한국어와 법령 원문 사이의 어휘 차이 때문에 검색 품질이 떨어진다. GPT-5-mini로 사용자 질문을 법령에서 쓰일 만한 표현으로 한 번 다듬는다. 예를 들어 전세금 못 받았다 같은 입력은 임대차 보증금 반환, 임대인 채무 불이행 같은 표현이 들어간 형태로 재작성된다. 이 단계는 사고가 깊을 필요가 없고 어휘 매핑 위주라 작은 모델이 더 빠르고 비용이 낮다.
6.2. HyDE - Hypothetical Document Embeddings
Query Rewrite로도 부족할 때 한 단계 더 들어간다. HyDE는 사용자 질문에 대한 가상 답변을 LLM이 한 번 생성하고 그 가상 답변을 임베딩해 검색에 쓰는 기법이다. 질문 임베딩 대신 답변 형태에 가까운 임베딩이 만들어지므로 같은 답변을 담고 있는 실제 문서와의 코사인 유사도가 더 높게 나온다. 양실장에서는 GPT-5-mini로 가상 법령 풀이 답변을 두 문단 정도 만들어 그 결과를 임베딩한다. 자세한 원리는 별도 글 [LLM] HyDE - Hypothetical Document Embeddings에서 다뤘다.
부동산 도메인에서는 HyDE의 효과가 즉각적으로 보였다. 같은 질문을 두고 raw query 임베딩과 HyDE 임베딩으로 검색했을 때 정답 조항의 rank가 평균적으로 위로 올라갔고 특히 사용자 질문이 짧고 일상어일수록 격차가 커졌다. 한 줄짜리 질문(예: 전세 보증금 못 받으면 어떡해요?)은 임베딩 자체가 맥락이 부족해서 ANN top-10 안에 정답이 들어오지 않는 경우가 흔한데 HyDE를 거치면 가상 답변 안에 임대차보호법, 보증금 반환 청구권, 우선변제권 같은 법령 어휘가 자연스럽게 등장하면서 검색 표상이 정답 청크 쪽으로 끌려간다.
HyDE의 대가는 호출 한 번이 추가된다는 점이다. Query Rewrite 다음에 HyDE까지 거치면 검색 전 LLM 호출이 두 번이고 그만큼 응답 시간이 늘어난다. 이 비용을 줄이려고 두 단계를 GPT-5-mini로 묶고 최대 토큰을 짧게 잡아 응답 지연을 누른다. 가상 답변은 두 문단 안팎으로 충분하고 그 이상 길어지면 임베딩 평균이 흐려져 오히려 검색 품질이 떨어진다.
부동산 도메인 외 일반 질문이 들어오는 경우(예: 양실장 누구야?)에는 HyDE 노드가 빠지도록 분기를 두었다. Query Rewrite 노드의 출력 JSON에 domain_match: bool 플래그를 넣어 LangGraph 조건 엣지에서 HyDE 우회 경로로 보낸다. 도메인 밖 질문은 그냥 정중히 거절 답변을 생성하는 짧은 경로로 끝낸다.
6.3. Embedding - Qwen3-Embedding-8B
임베딩 모델은 Qwen3-Embedding-8B를 DeepInfra 호스팅으로 썼다. 한국어 임베딩 품질이 좋다는 판단이었고 DeepInfra는 dedicated GPU 없이도 Qwen3 패밀리를 표준 OpenAI 호환 API로 받아주기 때문에 사이드 프로젝트 비용 곡선에 잘 맞았다.
DeepInfra를 고른 이유를 한 줄 더 적자면 Qwen3 패밀리의 임베딩과 리랭커를 같은 사업자 한 곳에서 받을 수 있다는 운영적 단순함이 컸다. 키 한 벌, 빌링 한 건, 호환 API 스키마 하나로 두 모델을 다 다룬다.
6.4. Vector Search - Milvus ANN Index
벡터 DB는 Milvus다. 검색은 BM25 + ANN 하이브리드로 돌린다. 법령 조항은 조항 번호나 정의 어휘가 정확히 일치할 때 BM25가 결정타가 되는 경우가 있어서 ANN만으로는 잡히지 않는 매칭을 BM25가 받쳐줬다.
6.5. Reranker - Qwen3-Reranker-8B
ANN 검색 결과를 그대로 컨텍스트로 쓰지 않고 리랭커로 다시 정렬한다. 부동산 법령은 비슷한 단어가 다른 의미로 쓰이는 경우가 많아서(예: 임대 vs 임차, 소유권 vs 사용권) ANN의 코사인 유사도만으로는 정답 조항이 뒤로 밀리는 경우가 있었다. 리랭커는 query와 candidate 쌍을 직접 채점하기 때문에 이런 의미 충돌을 잡아준다.
리랭커는 Qwen3-Reranker-8B를 골랐다. 한국어 법률 도메인에서 다른 후보 대비 안정적이라는 판단이었고 임베딩과 같은 Qwen3 패밀리에서 동작한다는 점도 결정에 영향을 미쳤다. 두 모델이 같은 백본에서 파생되어 표상 공간이 비슷하기 때문에 임베딩이 뽑은 후보를 리랭커가 다시 보았을 때 표상 어긋남이 적다.
6.6. Generation - GPT-5.4 Streaming
마지막 답변 생성은 GPT-5.4를 OpenAI Streaming으로 받는다. 시스템 프롬프트로 페르소나(부동산 베테랑 양실장), 답변 형식(요약 → 근거 → 인용), 그리고 컨텍스트 외 추론 금지 규칙을 박아둔다. 토큰이 흐를 때마다 SSE로 delta 이벤트를 보내고 검색 단계에서 추출한 인용 출처 메타데이터는 답변 생성이 끝난 직후 citations 이벤트로 한 번에 흘려보낸다. 컨텍스트는 리랭커가 뽑은 청크를 시스템 프롬프트 뒤에 user 메시지로 붙여 넣고 모델이 출처 라벨을 답변 안에 자연스럽게 끼워 넣을 수 있도록 청크 앞에 출처 라벨을 명시적으로 박아둔다.
7. Data Ingestion Layer - 법제처 → Kafka → Milvus
법령과 판례 원문은 법제처 국가법령정보 Open API에서 받아온다. 팀에서 별도로 정리해 둔 Open Law API 문서가 있어서 엔드포인트와 파라미터 매트릭스는 거기서 바로 확인했다.
수집 파이프라인은 Cron 스케줄러 → Kafka 토픽 → Worker → 임베딩 → Milvus 인제스트 순서다.
- Cron Scheduler가 갱신 주기에 맞춰 법제처 API를 호출한다
- 수집 결과는 Kafka 토픽에 이벤트로 발행한다. 인제스트가 RAG 파이프라인과 비동기로 흐르도록 분리한 자리다
- Worker가 Kafka에서 이벤트를 컨슈머로 받아 원문 파싱과 정규화, 청킹을 수행한다
- 청크 단위 텍스트를 임베딩 모델로 보내 벡터를 만든다. 같은 모델을 검색 시점에도 그대로 써야 표상 공간이 어긋나지 않는다
- 임베딩 결과를 Milvus에 적재한다. 동시에 원문 청크는 MongoDB에도 저장해서 답변 인용 시 원본 텍스트를 그대로 보여줄 수 있게 한다
청킹 전략은 영역마다 다르게 잡았다. 법령은 조항이 자연스러운 의미 단위라 조항 단위로 자르고 너무 긴 조항은 항/호 단위로 한 번 더 쪼갠다. 판례는 판결문 구조(판시사항, 판결요지, 이유, 주문)가 정해져 있어 그 구조를 살려 의미 단위로 청킹했다.
Kafka를 굳이 끼운 이유는 인제스트가 RAG 파이프라인과 완전히 비동기여야 했기 때문이다. 새 법령이 들어오는 동안 사용자 채팅이 멈추면 안 되고 인제스트 실패는 인덱싱 실패로 끝나야지 채팅 실패로 번지면 안 된다. Kafka가 두 영역 사이의 안전벨트 역할을 한다.
8. Milvus 한국어 토크나이저 - lindera-ko-dic 커스텀 빌드
이 절이 양실장에서 가장 시간 잡아먹은 부분이다. Milvus 풀텍스트 검색은 Tantivy 위에서 동작하고 Tantivy의 토크나이저는 Lindera를 통해 일본어 사전(IPADIC, UniDic)이나 한국어 사전(ko-dic)을 붙일 수 있다. 문제는 Milvus 공식 도커 이미지가 일본어 사전 빌드만 포함한다는 점이다. 한국어를 그대로 먹였더니 BM25 매칭이 1글자 단위로 깨지고 풀텍스트 하이브리드 검색이 사실상 무용지물이 되었다.
해결은 Milvus를 한국어 사전으로 직접 빌드하는 것이었다. milvus 포크에 feat/ko-dic-build 브랜치를 따고 Dockerfile.ko-dic을 추가했다. 핵심은 빌드 인자 한 줄이다.
ARG TANTIVY_FEATURES=lindera-ko-dic
RUN make milvus TANTIVY_FEATURES=${TANTIVY_FEATURES}
milvusdb/milvus-env:ubuntu22.04-... 이미지를 빌더로 잡고 그 위에서 TANTIVY_FEATURES=lindera-ko-dic을 박아 컴파일한다. 결과물(*.so + Go 바이너리)은 두 번째 스테이지의 ubuntu:jammy 위로 복사하고 LD_LIBRARY_PATH=/milvus/lib, LD_PRELOAD=/milvus/lib/libjemalloc.so까지 잡아 운영 이미지를 굽는다.
이렇게 빌드한 이미지에서 text_analyzer로 ko-dic을 지정하면 한국어 형태소 단위 토크나이즈가 동작한다. BM25 + ANN 하이브리드 검색에서 한국어 정확도가 다시 살아났다.
9. SSE 이벤트 프로토콜
클라이언트와 AI API 사이의 SSE 이벤트 시퀀스는 아키텍처 도식 맨 아래 줄에 그대로 그려져 있다.
room
→ query_analysis_start → query_analysis_end
→ hyde_start → hyde_end
→ retrieve_start → retrieve_end
→ generate_start → delta×N → citations → generate_end
→ end
각 이벤트가 하나의 SSE event: 타입이고 data: 페이로드는 단계별로 다르다. query_analysis_end에는 재작성된 쿼리, hyde_end에는 가상 답변, retrieve_end에는 검색된 청크 정보, delta에는 토큰 조각, citations에는 인용 메타데이터(법령명, 조항 번호, 판례 번호, 원문 키)가 실린다.
end 이벤트는 명시적인 스트림 종료 신호다. 일반적인 SSE에서는 서버가 연결을 닫으면 클라이언트가 종료를 인지하지만 명시적인 종료 이벤트가 있으면 정상 종료와 비정상 종료를 구분하기 쉽다.
10. 배포 - 동생이 처리한 영역
AWS 배포 영역은 이 글에서 깊이 다루지 않는다. Terraform으로 EKS 위에 인프라를 정의해 띄우는 형태로 동생이 직접 처리한 영역이고 본인에게는 익숙하지 않은 영역이라 디테일은 다음 사이클로 자연스럽게 미뤘다. 컨테이너 이미지 빌드와 ECR 업로드, 환경별 설정 주입 정도만 흐릿하게 같이 봤고 클러스터 토폴로지나 IAM 정책 같은 영역은 동생의 손에 통째로 맡겼다. RAG 파이프라인 안쪽에 시간을 다 쓰고 나니 인프라까지 깊이 보겠다는 욕심이 나오지 않았던 것이 솔직한 이유이기도 하다.
11. 무엇을 배웠나 - 그리고 무엇이 빠져 있나
사이드 프로젝트로 양실장을 굴리면서 RAG에 대한 인상이 많이 바뀌었다. RAG는 단순히 검색 + 생성을 묶는 패턴이 아니라 인덱스 품질, 토크나이저, 임베딩, 리랭커, 컨텍스트 구성, 출처 노출 같은 영역이 모두 한 줄에 꿰어져야 결과가 나오는 통합 파이프라인이라는 사실을 코드 레벨에서 직접 만져 보았다. 한 군데만 부실해도 답변 품질이 즉시 떨어지고 그 부실함은 사용자에게 인용 출처 형태로 그대로 노출된다. 환각을 줄이기 위해 출처를 보여주는 RAG의 미덕은 동시에 시스템 자체의 약한 지점을 그대로 드러내는 거울이기도 했다.
부동산이라는 좁은 도메인 안에서 시작했지만 같은 파이프라인이 의료, 세무, 보험 같은 다른 라이선스 산업으로도 그대로 옮겨갈 수 있다는 감을 잡았다. 도메인 어휘만 갈아끼우면 되는 영역이 의외로 컸고 핵심 자산은 형태소 단위 토크나이저 + 임베딩/리랭커 조합 + 인용 가능한 데이터 소스 세 가지에 모이는 것 같다.
한편 일반적인 에이전트가 제공하는 기능 중에 양실장이 채우지 못한 영역도 분명히 있다. 동적 툴 서치(질문에 맞는 외부 도구를 자동 선택), 컨텍스트 압축(긴 대화에서 의미를 보존하며 토큰을 줄임), 멀티턴 메모리 관리, 자기 검증(self-critique) 같은 기능은 v1 범위에서 손대지 못했다. 동생이 본업으로 바빠서 사이드 프로젝트 호흡이 꾸준하지 않았고 우선순위가 높은 RAG 파이프라인과 한국어 토크나이저, 인덱스 품질 쪽에 시간이 먼저 몰렸다. 일반 에이전트의 기능 셋으로 한 단계 더 나아가는 작업은 다음 사이클로 미뤄두었다.
이 사이클을 밀어붙이는 데 시간 자체도 만만치 않게 들어갔다. 거의 두 달 가까이 작업이 길어지는 날에는 밤늦게까지 사이드 프로젝트와 공부에 붙어 있었다. 본업 일과를 마무리한 늦은 저녁부터 시작해 한국어 토크나이저 빌드 한 번 깨지면 다시 빌드하는 데 몇 시간이 흐르고 임베딩/리랭커 비교 한 라운드 돌리면 또 몇 시간이 사라지는 식이었다. 내 전문 영역까지 에이전트로 대체되는 게 아닐까 하는 불안감과 에이전트가 안에서 실제로 어떻게 굴러가는지에 대한 학술적 궁금함이 함께 끌고 온 공부였지만 막상 들어가 보니 늦게까지 붙들어도 지치지 않을 만큼 흥미가 따라왔다. 사이드 프로젝트가 하나의 학습 가속기로 작동한 시간이었다.
한 발 더 나아가면 부동산 거래 자체의 업무 프로세스를 자동화하거나 보조하는 기능까지 만들어 볼 만했다. 공인중개사가 매물 등록, 계약서 작성, 권리 관계 확인, 시세 분석, 고객 응대 같은 일을 어떻게 굴리는지 그 흐름 안에서 어디가 가렵고 어디에 시간이 새는지 알아내야 진짜 도움이 되는 에이전트를 만들 수 있다. 그런데 본인은 그 도메인의 현장 감각이 없다. 부동산 거래를 직접 굴려본 적이 없으니 어떤 기능이 부족하고 어떤 자동화가 필요한지를 가늠하기 어려웠다. RAG로 법령 검색을 풀어 주는 정도까지가 도메인 지식 없이도 가닿을 수 있는 자리였고 그 너머는 이 사이드 프로젝트의 손이 닿지 않는 영역이었다.
결국 도메인이 핵심이라는 생각이 다시 뚜렷해졌다. AI 에이전트는 모델, 파이프라인, 인프라가 다 갖춰져 있어도 풀려는 문제가 정확히 정의되지 않으면 그 위에서 만든 기능은 사용자에게 가짜 효용을 주는 수준에서 멈춘다. 임베딩 모델을 어떻게 고를지보다 사용자의 어느 행동을 어떻게 줄여 줄지가 더 큰 결정이다. 양실장에서 우리가 할 수 있었던 것은 RAG 기술 스택을 끝까지 한 번 굴려본 일이고 진짜 제품으로 가져가려면 도메인 전문가가 들어와 가려운 부분을 짚어줘야 한다는 사실을 거꾸로 확인한 셈이다.
양실장 사이드 프로젝트는 여기까지로 일단 마무리한다. 두 달 가까이 늦은 시간까지 붙들면서 체력도 호흡도 한 번 바닥을 친 시기였고 RAG 파이프라인을 통째로 한 사이클 굴려본다는 1차 목표는 충분히 달성했다고 본다. 다음 사이클은 이 자리에서 멈추고 다른 영역으로 옮겨갈 예정이다. 양실장에서 깨달은 도메인의 무게는 다음 프로젝트를 고르는 기준에 그대로 반영될 것 같다.
마지막으로 동생과 같이 짠 경험 자체가 가장 큰 수확이었다. 현업에서 매일 RAG와 LangGraph를 다루는 사람과 옆에 붙어 페어하다 보면 책으로 봐서 안 보이던 디테일이 한꺼번에 들어온다. 동생 덕분에 책 한 권 분량의 공부가 평일 저녁 페어 몇 번으로 압축되어 들어왔다. 임베딩 모델 선택부터 청킹 전략, 리랭커 평가 방식, LangGraph 노드 디자인, SSE 이벤트 프로토콜 설계까지 실전에서 어떤 결정이 먹히고 어떤 결정이 깨지는지를 옆에서 받아들일 수 있었다. 이 사이드 프로젝트의 가벼운 포맷이 평일 저녁에도 부담 없이 부딪힐 수 있게 해줬고 결과적으로 학습 곡선이 가장 가파른 구간을 가장 빠른 속도로 통과한 시기가 되었다.
참고
담당자:
- 기획
- binaryloader
- 리서치
- binaryloader
- 초안
- binaryloader
- 편집
- binaryloader
- 리뷰
- binaryloader
- 번역
- Claude
- 썸네일
- Claude
- 발행
- Claude



댓글남기기